add first
This commit is contained in:
parent
313d00403d
commit
1bd82c28c1
|
|
@ -0,0 +1,39 @@
|
|||
---
|
||||
title: Aria2 for Docker
|
||||
date: 2022-05-31 19:43:50.958
|
||||
updated: 2023-05-06 10:54:45.616
|
||||
url: /archives/aria2
|
||||
categories:
|
||||
- Docker
|
||||
tags:
|
||||
- Docker
|
||||
---
|
||||
|
||||
# Docker aria2-pro
|
||||
|
||||
```
|
||||
docker run -d \
|
||||
--name aria2-pro \
|
||||
--restart unless-stopped \
|
||||
--log-opt max-size=1m \
|
||||
--network host \
|
||||
-e PUID=$UID \
|
||||
-e PGID=$GID \
|
||||
-e RPC_SECRET=byj111 \
|
||||
-e RPC_PORT=6800 \
|
||||
-e LISTEN_PORT=6888 \
|
||||
-v $PWD/aria2-config:/config \
|
||||
-v $PWD/aria2-downloads:/downloads \
|
||||
p3terx/aria2-pro
|
||||
```
|
||||
|
||||
# AriaNg webUI for control
|
||||
用来管理aria2的UI界面
|
||||
```
|
||||
docker run -d \
|
||||
--name ariang \
|
||||
--restart unless-stopped \
|
||||
--log-opt max-size=1m \
|
||||
-p 6880:6880 \
|
||||
p3terx/ariang
|
||||
```
|
||||
|
|
@ -0,0 +1,107 @@
|
|||
---
|
||||
title: Docker搭建DST饥荒游戏专用服务器
|
||||
date: 2021-07-15 10:14:59.049
|
||||
updated: 2023-06-16 22:22:42.255
|
||||
url: /archives/dstfordocker
|
||||
categories:
|
||||
- Docker
|
||||
tags:
|
||||
- Docker
|
||||
---
|
||||
|
||||
> 几个云大厂新用户活动白嫖了几个轻量服务器哈哈,Github上看到有人做了游戏服务器镜像,非常方便,拿过来run一下,记录一下搭建过程,写的比较简洁,适合对Linux有一点点了解或者爱折腾的同学
|
||||
|
||||
> 当前环境为Ubuntu18.04,1核2G,阿里云ECS
|
||||
|
||||
# 拉取镜像
|
||||
|
||||
拉取镜像
|
||||
```
|
||||
docker pull jamesits/dst-server
|
||||
```
|
||||
|
||||

|
||||
|
||||
启动容器
|
||||
```
|
||||
docker run -v ${HOME}/.klei/DoNotStarveTogether:/data --name Cluster -d -p 10999-11000:10999-11000/udp -p 12346-12347:12346-12347/udp -it jamesits/dst-server:latest
|
||||
```
|
||||
|
||||
# 修改游戏配置文件
|
||||
|
||||
启动容器后查看日志会发现报错,没关系,这是因为缺少一些配置
|
||||
|
||||
以下为游戏文件所在路径
|
||||
```
|
||||
~/.klei/DoNotStarveTogether/DoNotStarveTogether/Cluster_1
|
||||
```
|
||||
|
||||
## cluster_token.txt
|
||||
这个token需要自行去生成,打开游戏后,点击`账户>游戏>饥荒联机版的游戏服务器`,生成一个token令牌,类似于下图的字符串,把它复制下来写入到cluster_token.txt中
|
||||
或者
|
||||
也可以复制网址https://accounts.klei.com/并打开,使用你的steam账号登录后去生成token
|
||||

|
||||
|
||||
<br/>
|
||||
|
||||
## Caves
|
||||
打开游戏新建一个档,配置好世界和mod,进入游戏,选人物时退出。打开你刚刚建的那个档的游戏文件,文件夹名字就是cluster_x,生成的档是第一个x就为1。把cluster_x中的Caves文件夹中的leveldataoverride.lua和modoverrides.lua文件复制到服务器.klei文件夹对应的Caves文件夹里,并且删除掉服务器Caves里的worldgenoverride.lua文件
|
||||

|
||||
|
||||
<br/>
|
||||
|
||||
## Master
|
||||
与Caves文件夹类似,打开cluster_x,把Master中的leveldataoverride.lua和modoverrides.lua文件复制到docker容器中的Master文件夹里,并且,同样删除掉worldgenoverride.lua文件
|
||||

|
||||
|
||||
<br/>
|
||||
|
||||
## mods
|
||||
使用vim打开dedicated_server_mods_setup.lua文件,再打开cluster_x中的modoverrides.lua文件,把mod的标识(就是那串数字)按照下面图片的格式写入到dedicated_server_mods_setup.lua文件中
|
||||

|
||||
|
||||
<br/>
|
||||
|
||||
## cluster.ini
|
||||
这个文件是配置专用服务器的一些基本信息
|
||||
cluster_name 服务器名称
|
||||
cluster_description 服务器备注
|
||||
cluster_password 服务器密码
|
||||
cluster_language = zh 服务器语言(zh中文,en英语)
|
||||
PVP 游戏模式是否开启PVP
|
||||
max_players 房间可以容纳的人数限制
|
||||
如果你不知道其它配置的作用,就不要改动,只修改上述的参数就可以了
|
||||

|
||||
|
||||
<br/>
|
||||
|
||||
## 常用命令
|
||||
暂停服务器
|
||||
```
|
||||
docker stop Cluster_1
|
||||
```
|
||||
|
||||
重启容器(重启需要一点时间大概一分钟左右完成,可以查看日志)
|
||||
```
|
||||
docker restart Cluster_1
|
||||
```
|
||||
|
||||
查看日志(Ctrl+C退出)
|
||||
```
|
||||
docker logs -f --tail 20 Cluster_1
|
||||
```
|
||||
|
||||
备份服务器(备份路径/usr/local/klei.tar.gz)
|
||||
```
|
||||
tar -zcvf /usr/local/klei.tar.gz /root/.klei/
|
||||
```
|
||||
|
||||
# 我遇到的一些问题,希望对你有帮助
|
||||
1. 游戏更新或mod更新导致了一些问题,重启容器就会自动更新
|
||||
2. 服务器进不去或者搜不到可以尝试重启容器再尝试下
|
||||
3. 发现在游戏内制作物品时皮肤无效,重启容器再试下
|
||||
4. 在重启容器时查看日志发现更新进度非常缓慢,可以尝试暂停容器并rm掉,重新启一个容器。如果还是非常缓慢,个人猜测可能是因为更新发布的游戏文件还没有同步至最近的节点,可以过一段时间重试重启试下
|
||||
5. 我有尝试过把本地存档迁移至服务器端,但是出现了一些奇怪的问题,"例如只听到猎狗叫声,却不出现猎狗",这个没有太想深究
|
||||
6.
|
||||
|
||||
<a href="https://github.com/Jamesits/docker-dst-server" target="_blank">镜像原作者jamesits/dst-server </a>
|
||||
|
|
@ -0,0 +1,73 @@
|
|||
---
|
||||
title: Docker搭建SVN-Server及WebSVN
|
||||
date: 2023-07-25 17:33:02.904
|
||||
updated: 2023-07-25 17:34:36.389
|
||||
url: /archives/docker-da-jian-svn-server-ji-websvn
|
||||
categories:
|
||||
- Docker
|
||||
- Tools
|
||||
tags:
|
||||
- Docker
|
||||
- Tools
|
||||
---
|
||||
|
||||
# Docker搭建SVN-Server及WebSVN
|
||||
|
||||
## 搭建
|
||||
|
||||
拉取镜像
|
||||
|
||||
```shell
|
||||
docker pull elleflorio/svn-server
|
||||
```
|
||||
|
||||
运行镜像
|
||||
|
||||
```shell
|
||||
docker run -d --name svn --restart=always -v /usr/local/svnData:/home/svn -p 13690:80 -p 3690:3690 elleflorio/svn-server
|
||||
```
|
||||
|
||||
创建管理员用户
|
||||
|
||||
```shell
|
||||
docker exec -t svn htpasswd -b /etc/subversion/passwd <username> <password>
|
||||
```
|
||||
|
||||
对持久Volume添加write权限
|
||||
|
||||
```shell
|
||||
chmod -R 777 /usr/local/svnData
|
||||
```
|
||||
|
||||
## 进入SVN仓库URL
|
||||
|
||||
浏览器地址栏输入http://ip:13690/svn,此时会让你输入用户名和密码,用户密码即上面命令行创建的用户和密码,进入后就可以看到仓库列表
|
||||
|
||||
浏览器地址栏输入http://ip:13690/svnadmin,第一次进入会进行后台的配置管理
|
||||
|
||||
| 配置名称 | Value |
|
||||
| ---------------------------------------------------- | ----------------------------------------- |
|
||||
| Subversion authorization file | /etc/subversion/subversion-access-control |
|
||||
| User authentication file (SVNUserFile) | /etc/subversion/passwd |
|
||||
| User view provider type | passwd |
|
||||
| User edit provider type | passwd |
|
||||
| Group view provider type | svnauthfile |
|
||||
| Group edit provider type | svnauthfile |
|
||||
| Repository view provider type | svnclient |
|
||||
| Repository edit provider type | svnclient |
|
||||
| Parent directory of the repositories (SVNParentPath) | /home/svn |
|
||||
| Subversion client executable | /usr/bin/svn |
|
||||
| Subversion admin executable | /usr/bin/svnadmin |
|
||||
|
||||
以上配置填写好后进行test测试,Test passed后再进行保存配置信息,特别注意Parent directory of the repositories (SVNParentPath)一定要Test passed
|
||||
|
||||
## 创建仓库及仓库授权
|
||||
|
||||
进入http://ip:13690/svnadmin/repositorycreate.php页面进行创建仓库,输入仓库名称、选择仓库类型(默认是文档系统)及预设仓库结构,点击create
|
||||
|
||||
进入http://ip:13690/svnadmin/accesspathslist.php页面选择已创建的仓库进行用户或组及操作权限(只读及读写)授权
|
||||
|
||||
授权完成后就可以进行仓库内容VCS了
|
||||
|
||||
|
||||
For https://www.cnblogs.com/zepc007/p/14521394.html
|
||||
|
|
@ -0,0 +1,104 @@
|
|||
# git基本使用
|
||||
|
||||
## Git的安装
|
||||
|
||||
官网:https://git-scm.com/downloads
|
||||
|
||||
## Git基本概念
|
||||
|
||||
工作区 -> 暂存区 -> 版本库
|
||||
|
||||
## Git常用操作
|
||||
|
||||
### 仓库初始化
|
||||
|
||||
```sh
|
||||
git init
|
||||
```
|
||||
|
||||
### 提交到暂存区
|
||||
|
||||
```sh
|
||||
# 提交当前全部
|
||||
git add .
|
||||
# 提交指定文件
|
||||
git add fileName
|
||||
```
|
||||
|
||||
### 从暂存区checkout文件(相当于恢复到修改前的状态)
|
||||
|
||||
```sh
|
||||
git checkout -- fileName
|
||||
```
|
||||
|
||||
### 提交版本库
|
||||
|
||||
```sh
|
||||
git commit -m '备注'
|
||||
```
|
||||
|
||||
### git push
|
||||
|
||||
命令格式
|
||||
|
||||
```
|
||||
git push <远程主机名> <本地分支名>:<远程分支名>
|
||||
```
|
||||
|
||||
将本地的 master 分支推送到 origin 主机的 master 分支
|
||||
|
||||
```
|
||||
git push origin master
|
||||
```
|
||||
|
||||
等价于
|
||||
|
||||
```
|
||||
git push origin master:master
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
从版本库恢复最近一次版本(覆盖暂存区、工作区)
|
||||
|
||||
```sh
|
||||
# --hard 强制覆盖,会把暂存区和工作区内的文件一起覆盖
|
||||
git reset --hard head
|
||||
```
|
||||
|
||||
从版本库恢复最近一次版本(不会覆盖暂存区)
|
||||
|
||||
```sh
|
||||
git reset head
|
||||
```
|
||||
|
||||
回退指定版本
|
||||
|
||||
```
|
||||
git reset --hard 版本号
|
||||
```
|
||||
|
||||
|
||||
|
||||
查看日志
|
||||
|
||||
```
|
||||
git log
|
||||
```
|
||||
|
||||
```
|
||||
git log --graph
|
||||
```
|
||||
|
||||
```
|
||||
git log --online
|
||||
```
|
||||
|
||||
```
|
||||
git log --graph --online
|
||||
```
|
||||
|
||||
|
|
@ -0,0 +1,90 @@
|
|||
---
|
||||
title: Java子类能否访问父类私有属性?
|
||||
date: 2023-04-22 14:02:20.698
|
||||
updated: 2023-05-06 20:11:27.527
|
||||
url: /archives/java-zi-lei-neng-fou-fang-wen-fu-lei-si-you-shu-xing-
|
||||
categories:
|
||||
- Java
|
||||
tags:
|
||||
---
|
||||
|
||||
### 概念
|
||||
|
||||
继承就像是我们现实生活中的父子关系,儿子可以遗传父亲的一些特性,在面向对象语言中,就是一个类可以继承另一个类的一些特性,从而可以代码重用,其实继承体现的是is-a关系,父类同子类在本质上还是一类实体;子类通过继承父类的属性的行为,我们称之为继承。Java只支持单继承,不支持多继承。因为多继承容易带来安全隐患:当多个父类定义相同的功能,当功能内容不同的时候,子类对象不确定要运行哪一个,在Java中用另一种形式体现出来,就是接口的多实现。
|
||||
|
||||
### 子类能否继承父类私有属性或方法?
|
||||
|
||||
为验证这个问题,我们接着往下看
|
||||
|
||||
#### 观点一
|
||||
|
||||
Java官方文档原文
|
||||
|
||||
```
|
||||
## Private Members in a Superclass
|
||||
|
||||
A subclass does not inherit the `private` members of its parent class. However, if the superclass has public or protected methods for accessing its private fields, these can also be used by the subclass.
|
||||
|
||||
A nested class has access to all the private members of its enclosing class—both fields and methods. Therefore, a public or protected nested class inherited by a subclass has indirect access to all of the private members of the superclass.
|
||||
```
|
||||
|
||||
详细链接:[docs.oracle.com/javase/…](https://docs.oracle.com/javase/tutorial/java/IandI/subclasses.html)
|
||||
|
||||
意思是说:**子类不能继承父类的私有属性,但是如果子类中公有的方法影响到了父类私有属性,那么私有属性是能够被子类使用的。**
|
||||
|
||||
#### 观点二
|
||||
|
||||
其他人的理解:
|
||||
|
||||
父类的任何成员变量都是会被子类继承下去的。子类继承父类,子类拥有了父类的所有属性和方法。父类的私有属性和方法子类是无法直接访问的。当然私有属性可以通过public修饰的get和set方法访问到的,但是私有方法不行。父类的private属性,会被继承并且初始化在子类父对象中,只不过对外不可见。
|
||||
|
||||
**详解**:分析内存后,会发现,当一个子类被实例化的时候,默认会先调用父类的构造方法对父类进行初始化,即在内存中创建一个父类对象,然后再父类对象的外部放上子类独有的属性,两者合起来成为一个子类的对象。
|
||||
|
||||
所以:子类继承了父类的所有属性和方法或子类拥有父类的所有属性和方法是对的,只不过父类的私有属性和方法,子类是无法直接访到的。**即只是拥有,但是无法使用**。 (这里不考虑Java反射机制)
|
||||
|
||||
#### 辨析
|
||||
|
||||
**从继承的概念来说**,`private`和`final`不被继承。Java官方文档上是这么说的。
|
||||
|
||||
**从内存的角度来说**,父类的一切都被继承(从父类构造方法被调用就知道了,因为new一个对象,就会调用构造方法,子类被new的时候就会调用父类的构造方法,所以从内存的角度来说,子类拥有一个完整的父类)。子类对象所引用的内存有父类变量的一份拷贝。
|
||||
|
||||
如图所示,父类为`Person`类,子类为`Student`类。首先明确子类不能继承父类的构造方法。这就是为什么子类的默认的构造方法会自动调用父类的默认的构造方法。在子类的构造方法中通过`super()`方法调用父类的构造方法。也就是,在构造子类的同时,为子类构造出跟父类相同的域。如此就在子类的对象中,也拥有了父类声明的域了。
|
||||
|
||||
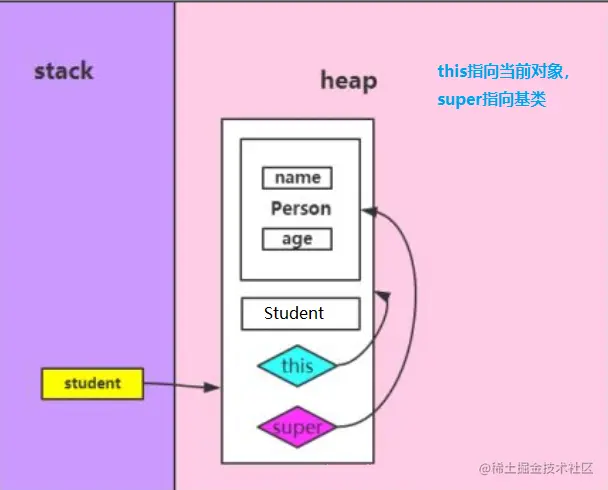
|
||||
|
||||
如果一个子类继承了父类,那么这个子类拥有父类所有的成员属性和方法,即使是父类里有`private`属性的变量,子类也是继承的,只不过不能使用,也就是说,它继承了,但是没有使用权,似乎又点矛盾,用我们通俗的说法就是 只能看,不能用,虽然是这样,但是,我们还是可以通过`set`和`get`的方法来间接的访问父类中的`private`属性的变量。
|
||||
|
||||
关于成员变量的继承,父类的任何成员变量都是会被子类继承下去的,这些继承下来的私有成员虽对子类来说不可见,但子类仍然可以用父类的函数操作他们。
|
||||
|
||||
这样的设计的意义就是我们可以用这个方法将我们的成员保护得更好,让子类的设计者也只能通过父类指定的方法修改父类的私有成员,这样将能把类保护得更好,这对一个完整的继承体系是尤为可贵的。
|
||||
|
||||
### 注意点
|
||||
|
||||
#### 成员变量和方法
|
||||
|
||||
- 子类`只能`继承父类的所有`非私有`的成员变量和方法。`可以`继承`public protected` 修饰的成员,`不可以`继承`private`修饰的。
|
||||
- 但是可以通过父类中提供的`public`的`setter`和`getter`方法进行间接的访问和操作`private`的属性
|
||||
- 对于子类可以继承父类中的成员变量和成员方法,如果`子类`中出现了和`父类同名的成员变量和成员方法`时,`父类`的`成员变量会被隐藏`,父类的`成员方法会被覆盖`。需要使用父类的成员变量和方法时,就需要使用`super`关键字来进行`引用`。
|
||||
- 当创建一个子类对象时,`不仅会为该类的实例变量分配内存`,也会为它`从父类继承得到的所有实例变量分配内存`,即使子类定义了与父类中同名的实例变量。 即依然会为父类中定义的、被隐藏的变量分配内存。
|
||||
- 如果`子类中的实例变量被私有`了,其父类中的同名实例变量`没有被私有`,那么子类对象就无法直接调用该变量,但可以通过`先将对象变量强制向上转型为父类型`,在通过该对象引用变量来访问那个实例变量,就会得到的是父类中的那个实例变量。
|
||||
|
||||
#### 构造器
|
||||
|
||||
- `子类不能继承获得父类的构造方法`,但是可以通过`super`关键字来访问`父类`构造方法。
|
||||
- 在一个构造器中`调用另一个重载构造器`使用`this`调用完成,在子类构造器中调用`父类构造器`使用`super`调用来完成。
|
||||
- super 和 this 的调用都`必须是在第一句`,否则会产生编译错误,this和super`只能存在一个`。
|
||||
- 不能进行`递归构造器调用`,即多个构造器之间互相循环调用。
|
||||
|
||||
### 总结
|
||||
|
||||
最后关于Java中子类能否继承父类的私有变量和方法?当然是以 Java 官方文档解释说明为准,这里我们明确一下“**继承**”一词的概念,在 Java 中,继承一词的意义是有限制的。一个子类只能继承其父类可访问的成员,并且该子类没有覆盖或者说隐藏父类中的那些可访问成员。所以,一个类的成员就是指在这个类中所声明的属性和方法,再加上从其父类继承而来的属性和方法。也就是说,子类是不能继承父类的私有成员的。
|
||||
|
||||
虽然子类不继承父类中的私有成员,但是在父类中的这些私有成员仍然是子类对象的一部分。因为在实例化对象的时候,只初始化在当前类中所声明的属性明显是不足够的,还需要初始化其父类中所有声明的属性。在实例化的过程中,JVM 需要为对象的类及其父类中所有定义的属性分配空间,包括父类中声明的私有成员。
|
||||
|
||||
所以,我们可以说:**子类不能从父类继承私有成员,但是子类的对象是包括子类所不能从父类中继承的私有成员的**。
|
||||
|
||||
|
||||
|
||||
|
||||
原文链接:https://juejin.cn/post/7023580206099071007
|
||||
|
||||
|
|
@ -0,0 +1,51 @@
|
|||
---
|
||||
title: Linux挂载硬盘
|
||||
date: 2023-05-31 12:02:12.526
|
||||
updated: 2023-05-31 12:02:12.526
|
||||
url: /archives/linux-gua-zai-ying-pan
|
||||
categories:
|
||||
- Linux
|
||||
tags:
|
||||
- Linux
|
||||
---
|
||||
|
||||
查看所有硬盘信息(找到需要挂载硬盘的路径,如/dev/vdb)
|
||||
```
|
||||
fdisk -l
|
||||
```
|
||||
2.创建挂载目录
|
||||
```
|
||||
mkdir /data
|
||||
```
|
||||
3.手动挂载分区(vdb:想要挂载的分区 data:分区挂载的目录)
|
||||
|
||||
```
|
||||
mount /dev/vdb /data
|
||||
```
|
||||
4.查看想要挂载分区的UUID
|
||||
```
|
||||
blkid /dev/vdb
|
||||
```
|
||||
5.修改开机挂载文件
|
||||
```
|
||||
vim /etc/fstab
|
||||
```
|
||||
6.文档末尾添加挂载信息
|
||||
```
|
||||
# 进入编辑模式:i 保存退出:Esc :wq 回车
|
||||
# [分区UUID] [挂载目录] [分区格式] [默认配置] [开机不检查硬盘] [交换分区]
|
||||
UUID=UUID /data ext4 defaults 0 0
|
||||
```
|
||||
7.取消挂载
|
||||
```
|
||||
umount /data
|
||||
```
|
||||
8.查看硬盘挂载情况
|
||||
```
|
||||
lsblk
|
||||
```
|
||||
```
|
||||
df -h
|
||||
```
|
||||
|
||||
转载链接:https://www.jianshu.com/p/2a5b6aae5d7b
|
||||
|
|
@ -0,0 +1,261 @@
|
|||
---
|
||||
title: Maven的基本使用
|
||||
date: 2023-04-22 16:18:15.469
|
||||
updated: 2023-05-13 10:35:29.575
|
||||
url: /archives/maven-jiao-cheng
|
||||
categories:
|
||||
- Java
|
||||
tags:
|
||||
---
|
||||
|
||||
## 1.安装Maven
|
||||
|
||||
### 1.1下载
|
||||
|
||||
Maven官网下载地址:https://maven.apache.org/download.cgi
|
||||
|
||||
### 1.2安装
|
||||
|
||||
解压至指定目录,例如我的路径就是`D:\apache-maven-3.9.1` ,路径里不要有中文或特殊符号
|
||||
|
||||
### 1.3修改本地仓库位置
|
||||
|
||||
Maven配置文件所在路径为:D:\apache-maven-3.9.1\conf\settings.xml
|
||||
|
||||

|
||||
|
||||
**记得要把 localRepository 标签从注释中拿出来**
|
||||
|
||||
### 1.4配置阿里云提供的镜像仓库
|
||||
|
||||
将原有的例子配置注释掉
|
||||
|
||||
加入阿里云镜像仓库
|
||||
|
||||
```xml
|
||||
<mirror>
|
||||
<id>nexus-aliyun</id>
|
||||
<mirrorOf>central</mirrorOf>
|
||||
<name>Nexus aliyun</name>
|
||||
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
|
||||
</mirror>
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 1.5配置基础 JDK 版本
|
||||
|
||||
Java 工程使用的默认 JDK 版本是 1.5,`profile` 标签整个复制到 `settings.xml` 文件的 `profiles` 标签内
|
||||
|
||||
```xml
|
||||
<profile>
|
||||
<id>jdk-1.8</id>
|
||||
<activation>
|
||||
<activeByDefault>true</activeByDefault>
|
||||
<jdk>1.8</jdk>
|
||||
</activation>
|
||||
<properties>
|
||||
<maven.compiler.source>1.8</maven.compiler.source>
|
||||
<maven.compiler.target>1.8</maven.compiler.target>
|
||||
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
|
||||
</properties>
|
||||
</profile>
|
||||
```
|
||||
|
||||
### 1.6配置Maven环境变量
|
||||
|
||||
`MAVEN_HOME`
|
||||
|
||||
`D:\apache-maven-3.9.1`
|
||||
|
||||
`PATH`
|
||||
|
||||
`%MAVEN_HOME%\bin`
|
||||
|
||||
> 配置环境变量的规律:
|
||||
>
|
||||
> XXX_HOME 通常指向的是 bin 目录的上一级
|
||||
>
|
||||
> PATH 指向的是 bin 目录
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 2. Maven 的使用
|
||||
|
||||
### 3.1 核心概念:坐标
|
||||
|
||||
**数学中的坐标**使用 x、y、z 三个『**向量**』作为空间的坐标系,可以在『**空间**』中唯一的定位到一个『**点**』。
|
||||
|
||||
|
||||
**Maven中的坐标**使用三个『**向量**』在『**Maven的仓库**』中**唯一**的定位到一个『**jar**』包。
|
||||
|
||||
- **groupId**:公司或组织的 id,即公司或组织域名的倒序,通常也会加上项目名称
|
||||
|
||||
例如:groupId:com.tofacebook.maven
|
||||
|
||||
- **artifactId**:一个项目或者是项目中的一个模块的 id,即模块的名称,将来作为 Maven 工程的工程名就是:module的名称
|
||||
|
||||
例如:artifactId:auth
|
||||
|
||||
- **version**:版本号
|
||||
|
||||
例如:version:1.0.0
|
||||
|
||||
提示:坐标和仓库中 jar 包的存储路径之间的对应关系,如下
|
||||
|
||||
```javascript
|
||||
<groupId>javax.servlet</groupId>
|
||||
<artifactId>servlet-api</artifactId>
|
||||
<version>2.5</version>
|
||||
```
|
||||
|
||||
复制
|
||||
|
||||
上面坐标对应的 jar 包在 Maven 本地仓库中的位置:
|
||||
|
||||
```javascript
|
||||
Maven本地仓库根目录\javax\servlet\servlet-api\2.5\servlet-api-2.5.jar
|
||||
```
|
||||
|
||||
复制
|
||||
|
||||
### 3.2 pom.xml
|
||||
|
||||
POM:**P**roject **O**bject **M**odel,项目对象模型。和 POM 类似的是:DOM(Document Object Model),文档对象模型。它们都是模型化思想的具体体现。
|
||||
|
||||
POM 表示将工程抽象为一个模型,再用程序中的对象来描述这个模型。这样我们就可以用程序来管理项目了。我们在开发过程中,最基本的做法就是将现实生活中的事物抽象为模型,然后封装模型相关的数据作为一个对象,这样就可以在程序中计算与现实事物相关的数据。
|
||||
|
||||
POM 理念集中体现在 Maven 工程根目录下 **pom.xml** 这个配置文件中。所以这个 pom.xml 配置文件就是 Maven 工程的核心配置文件。其实学习 Maven 就是学这个文件怎么配置,各个配置有什么用。
|
||||
|
||||
```javascript
|
||||
<!-- 当前Maven工程的坐标 -->
|
||||
<groupId>com.example</groupId>
|
||||
<artifactId>demo</artifactId>
|
||||
<version>0.0.1-SNAPSHOT</version>
|
||||
<name>demo</name>
|
||||
<description>Demo project for Spring Boot</description>
|
||||
<!-- 当前Maven工程的打包方式,可选值有下面三种: -->
|
||||
<!-- jar:表示这个工程是一个Java工程 -->
|
||||
<!-- war:表示这个工程是一个Web工程 -->
|
||||
<!-- pom:表示这个工程是“管理其他工程”的工程 -->
|
||||
<packaging>jar</packaging>
|
||||
<properties>
|
||||
<!-- 工程构建过程中读取源码时使用的字符集 -->
|
||||
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
|
||||
</properties>
|
||||
<!-- 当前工程所依赖的jar包 -->
|
||||
<dependencies>
|
||||
<!-- 使用dependency配置一个具体的依赖 -->
|
||||
<dependency>
|
||||
<!-- 在dependency标签内使用具体的坐标依赖我们需要的一个jar包 -->
|
||||
<groupId>junit</groupId>
|
||||
<artifactId>junit</artifactId>
|
||||
<version>4.12</version>
|
||||
<!-- scope标签配置依赖的范围 -->
|
||||
<scope>test</scope>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
```
|
||||
|
||||
复制
|
||||
|
||||
### 3.3 依赖
|
||||
|
||||
上面说到我们使用 Maven 最主要的就是使用它的依赖管理功能,引入依赖存在一个范围,maven的依赖范围包括: `compile`,`provide`,`runtime`,`test`,`system`。
|
||||
|
||||
- **compile**:表示编译范围,指 A 在编译时依赖 B,该范围为**默认依赖范围**。编译范围的依赖会用在编译,测试,运行,由于运行时需要,所以编译范围的依赖会被打包。
|
||||
- **provided**:provied 依赖只有当 jdk 或者一个容器已提供该依赖之后才使用。provide 依赖在编译和测试时需要,在运行时不需要。例如:servlet api被Tomcat容器提供了。
|
||||
- **runtime**:runtime 依赖在运行和测试系统时需要,但在编译时不需要。例如:jdbc 的驱动包。由于运行时需要,所以 runtime 范围的依赖会被打包。
|
||||
- **test**:test 范围依赖在编译和运行时都不需要,只在测试编译和测试运行时需要。例如:Junit。由于运行时不需要,所以 test 范围依赖不会被打包。
|
||||
- **system**:system 范围依赖与 provide 类似,但是必须显示的提供一个对于本地系统中 jar 文件的路径。一般不推荐使用。
|
||||
|
||||
| 依赖范围 | 编译 | 测试 | 运行时 | 是否会被打入jar包 |
|
||||
| :------- | :--- | :--- | :----- | :---------------- |
|
||||
| compile | √ | √ | √ | √ |
|
||||
| provided | √ | √ | × | × |
|
||||
| runtime | × | √ | √ | √ |
|
||||
| test | × | √ | × | × |
|
||||
| system | √ | √ | × | √ |
|
||||
|
||||
而在实际开发中,我们常用的就是 `compile`、`test`、`provided` 。
|
||||
|
||||
### 3.4 依赖的传递
|
||||
|
||||
A 依赖 B,B 依赖 C,那么在 A 没有配置对 C 的依赖的情况下,A 里面能不能直接使用 C?
|
||||
|
||||
再以上的前提下,C 是否能够传递到 A,取决于 B 依赖 C 时使用的依赖范围。
|
||||
|
||||
- B 依赖 C 时使用 compile 范围:可以传递
|
||||
- B 依赖 C 时使用 test 或 provided 范围:不能传递,所以需要这样的 jar 包时,就必须在需要的地方明确配置依赖才可以。
|
||||
|
||||
### 3.5 依赖的排除
|
||||
|
||||
当 A 依赖 B,B 依赖 C 而且 C 可以传递到 A 的时候,A 不想要 C,需要在 A 里面把 C 排除掉。而往往这种情况都是为了避免 jar 包之间的冲突。
|
||||
|
||||

|
||||
|
||||
所以配置依赖的排除其实就是阻止某些 jar 包的传递。因为这样的 jar 包传递过来会和其他 jar 包冲突。
|
||||
|
||||
一般通过使用`excludes`标签配置依赖的排除:
|
||||
|
||||
```javascript
|
||||
<dependency>
|
||||
<groupId>net.javatv.maven</groupId>
|
||||
<artifactId>auth</artifactId>
|
||||
<version>1.0.0</version>
|
||||
<scope>compile</scope>
|
||||
|
||||
<!-- 使用excludes标签配置依赖的排除 -->
|
||||
<exclusions>
|
||||
<!-- 在exclude标签中配置一个具体的排除 -->
|
||||
<exclusion>
|
||||
<!-- 指定要排除的依赖的坐标(不需要写version) -->
|
||||
<groupId>commons-logging</groupId>
|
||||
<artifactId>commons-logging</artifactId>
|
||||
</exclusion>
|
||||
</exclusions>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
复制
|
||||
|
||||
### 3.6 继承
|
||||
|
||||
#### 3.6.1 概念
|
||||
|
||||
Maven工程之间,A 工程继承 B 工程
|
||||
|
||||
- B 工程:父工程
|
||||
- A 工程:子工程
|
||||
|
||||
本质上是 A 工程的 pom.xml 中的配置继承了 B 工程中 pom.xml 的配置。
|
||||
|
||||
#### 3.6.2 作用
|
||||
|
||||
在父工程中统一管理项目中的依赖信息,具体来说是管理依赖信息的版本。
|
||||
|
||||
它的背景是:
|
||||
|
||||
- 对一个比较大型的项目进行了模块拆分。
|
||||
- 一个 project 下面,创建了很多个 module。
|
||||
- 每一个 module 都需要配置自己的依赖信息。
|
||||
|
||||
它背后的需求是:
|
||||
|
||||
- 在每一个 module 中各自维护各自的依赖信息很容易发生出入,不易统一管理。
|
||||
- 使用同一个框架内的不同 jar 包,它们应该是同一个版本,所以整个项目中使用的框架版本需要统一。
|
||||
- 使用框架时所需要的 jar 包组合(或者说依赖信息组合)需要经过长期摸索和反复调试,最终确定一个可用组合。这个耗费很大精力总结出来的方案不应该在新的项目中重新摸索。
|
||||
|
||||
通过在父工程中为整个项目维护依赖信息的组合既**保证了整个项目使用规范、准确的 jar 包**;又能够将**以往的经验沉淀**下来,节约时间和精力。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
参考:
|
||||
|
||||
https://blog.ideaopen.cn
|
||||
|
|
@ -0,0 +1,75 @@
|
|||
---
|
||||
title: Mysql5.7和8.0在Docker上的使用
|
||||
date: 2023-05-06 15:36:48.48
|
||||
updated: 2023-06-15 11:01:58.044
|
||||
url: /archives/mysql57-8-for-docker
|
||||
categories:
|
||||
- Docker
|
||||
- 数据库
|
||||
tags:
|
||||
- Docker
|
||||
- DB
|
||||
---
|
||||
|
||||
# Mysql5.7和8.0在Docker上的使用
|
||||
|
||||
8.0版本
|
||||
> 可以跟上正确的版本号
|
||||
```shell
|
||||
docker run -p 3306:3306 --name mysql8-test \
|
||||
-v /usr/local/docker/mysql/mysql-files:/var/lib/mysql-files \
|
||||
-v /usr/local/docker/mysql/conf:/etc/mysql/conf.d \
|
||||
-v /usr/local/docker/mysql/logs:/var/log/mysql \
|
||||
-v /usr/local/docker/mysql/data:/var/lib/mysql \
|
||||
-e MYSQL_ROOT_PASSWORD=root \
|
||||
-d mysql:latest
|
||||
```
|
||||
|
||||
5.7版本
|
||||
|
||||
```shell
|
||||
docker run -p 3306:3306 --name mysql5.7-test \
|
||||
-v /mydata/mysql/log:/var/log/mysql \
|
||||
-v /mydata/mysql/data:/var/lib/mysql \
|
||||
-v /mydata/mysql/conf:/etc/mysql \
|
||||
-e MYSQL_ROOT_PASSWORD=root -d mysql:5.7.42
|
||||
```
|
||||
|
||||
区别在于配置文件的路径不同
|
||||
|
||||
8版本是`/etc/mysql/conf.d`
|
||||
|
||||
5.7版本是`/etc/mysql`
|
||||
|
||||
## 查看用户信息,修改密码
|
||||
|
||||
```sql
|
||||
select host,user,plugin,authentication_string from mysql.user;
|
||||
```
|
||||
|
||||

|
||||
|
||||
修改root密码
|
||||
|
||||
```sql
|
||||
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
|
||||
```
|
||||
|
||||
修改root密码后再次查询用户信息,这个时候就可以远程连接成功了
|
||||
|
||||

|
||||
|
||||
## 报错日志
|
||||
|
||||
这个是在mysql8的镜像上启动容器,在run命令的时候挂载配置文件使用了/etc/mysql,报了以下错误
|
||||
|
||||
```sh
|
||||
[Note] [Entrypoint]: Entrypoint script for MySQL Server 8.0.33-1.el8 started.
|
||||
[ERROR] [Entrypoint]: mysqld failed while attempting to check config
|
||||
command was: mysqld --verbose --help --log-bin-index=/tmp/tmp.ixUqkEJ6Yi
|
||||
mysqld: Can't read dir of '/etc/mysql/conf.d/' (OS errno 2 - No such file or directory)
|
||||
mysqld: [ERROR] Stopped processing the 'includedir' directive in file /etc/my.cnf at line 36.
|
||||
mysqld: [ERROR] Fatal error in defaults handling. Program aborted!
|
||||
```
|
||||
|
||||
删除错误容器,重新启一个容器,把挂载配置文件目录的地方改一下就可以了
|
||||
|
|
@ -0,0 +1,36 @@
|
|||
---
|
||||
title: Office Tool Plus KMS
|
||||
date: 2022-06-21 17:12:46.239
|
||||
updated: 2023-02-13 21:43:05.849
|
||||
url: /archives/kms
|
||||
categories:
|
||||
- Tools
|
||||
tags:
|
||||
- Tools
|
||||
---
|
||||
|
||||
# Office Tool Plus KMS
|
||||
```
|
||||
使用Office Tool Plus安装微软全家桶,下面是一些KMS,如果不能激活多试几个
|
||||
```
|
||||
```
|
||||
kms.loli.beer
|
||||
kms.loli.best
|
||||
http://kms.cangshui.net
|
||||
http://kms.iaini.net
|
||||
kms.ddz.red
|
||||
http://kms.ghpym.com
|
||||
http://kms.qkeke.com
|
||||
http://kms.wxlost.com
|
||||
http://kms.heng07.com
|
||||
http://kms8.MSGuides.com
|
||||
http://kms.kuretru.com
|
||||
http://kms.moeclub.org
|
||||
http://kms.bige0.com
|
||||
http://kms.jm33.me
|
||||
http://kms.zhuxiaole.org
|
||||
http://home.aalook.com
|
||||
windows.kms.app
|
||||
nb.shenqw.win
|
||||
http://kms.magicwall.org
|
||||
```
|
||||
|
|
@ -0,0 +1,134 @@
|
|||
---
|
||||
title: Python发信示例
|
||||
date: 2022-05-31 11:31:44.524
|
||||
updated: 2023-02-13 21:38:40.253
|
||||
url: /archives/python-fa-xin-shi-li
|
||||
categories:
|
||||
- Python
|
||||
tags:
|
||||
- Python
|
||||
---
|
||||
|
||||
|
||||
> 当前Python环境版本为**3.9**
|
||||
# 无附件示例
|
||||
```python
|
||||
import smtplib
|
||||
from email.mime.text import MIMEText
|
||||
from email.utils import formatdate
|
||||
from email.header import Header
|
||||
import sys
|
||||
import importlib
|
||||
# 设置默认字符集为UTF8
|
||||
|
||||
default_encoding = 'utf-8'
|
||||
if sys.getdefaultencoding() != default_encoding:
|
||||
importlib.reload(sys)
|
||||
sys.setdefaultencoding(default_encoding)
|
||||
|
||||
# 发送邮件的相关信息(根据实际情况填写)
|
||||
smtpHost = ''
|
||||
smtpPort = '25'
|
||||
sslPort = '465'
|
||||
fromMail = ''
|
||||
toMail = 'rember1997@163.com'
|
||||
username = ''
|
||||
password = ''
|
||||
|
||||
# 邮件标题和内容
|
||||
subject = u'白云间的测试邮件'
|
||||
body = u'Hello,这是一封测试邮件' + fromMail
|
||||
|
||||
# 初始化邮件
|
||||
encoding = 'utf-8'
|
||||
mail = MIMEText(body.encode(encoding), 'plain', encoding)
|
||||
mail['Subject'] = Header(subject, encoding)
|
||||
mail['From'] = fromMail
|
||||
mail['To'] = toMail
|
||||
mail['Date'] = formatdate()
|
||||
|
||||
try:
|
||||
# 连接smtp服务器,明文/SSL方式,根据使用的SMTP支持情况选择一种
|
||||
# 普通方式,通信过程不加密
|
||||
# smtp = smtplib.SMTP(smtpHost,smtpPort)
|
||||
# smtp.ehlo()
|
||||
# smtp.login(username,password)
|
||||
#
|
||||
# 纯粹的ssl加密方式,通信过程加密,邮件数据安全
|
||||
# smtp = smtplib.SMTP(smtpHost, smtpPort)
|
||||
smtp = smtplib.SMTP_SSL(smtpHost, sslPort)
|
||||
smtp.ehlo()
|
||||
smtp.login(username, password)
|
||||
|
||||
# 发送邮件
|
||||
smtp.sendmail(fromMail, toMail, mail.as_string())
|
||||
smtp.close()
|
||||
print('OK')
|
||||
except Exception as e:
|
||||
print(e)
|
||||
```
|
||||
|
||||
# 邮件上传附件示例
|
||||
```python
|
||||
import smtplib
|
||||
import time
|
||||
from email.mime.text import MIMEText
|
||||
from email.mime.multipart import MIMEMultipart
|
||||
from email.header import Header
|
||||
localtime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
|
||||
|
||||
# 发送邮件的相关信息,根据实际情况填写
|
||||
smtpHost = ''
|
||||
smtpPort = '25'
|
||||
sslPort = '465'
|
||||
username = 'rember1997@163.com'
|
||||
password = ''
|
||||
fromMail = 'rember1997@163.com'
|
||||
toMail = ''
|
||||
subject = '白云间的SMTP邮件测试'
|
||||
body = '邮件发送测试\n \nby Python\n \n' + localtime
|
||||
encoding = 'utf-8'
|
||||
|
||||
# 创建
|
||||
mail = MIMEMultipart()
|
||||
mail['Subject'] = Header(subject, encoding)
|
||||
mail['From'] = Header("rember1997@163.com")
|
||||
mail['To'] = Header("byj@hz-qj.com")
|
||||
|
||||
# 正文内容
|
||||
mail.attach(MIMEText(body, 'plain', 'utf-8'))
|
||||
|
||||
# 构造附件1,上传当前目录下 test.txt 文件
|
||||
att1 = MIMEText(open('test.txt', 'rb').read(), 'base64', 'utf-8')
|
||||
att1["Content-Type"] = 'application/octet-stream'
|
||||
# filename即为邮件中附件的显示名称
|
||||
att1["Content-Disposition"] = 'attachment; filename="test.txt"'
|
||||
mail.attach(att1)
|
||||
# 构造附件2,传送当前目录下的 29M.zip 文件
|
||||
att2 = MIMEText(open('29M.zip', 'rb').read(), 'base64', 'utf-8')
|
||||
att2["Content-Type"] = 'application/octet-stream'
|
||||
att2["Content-Disposition"] = 'attachment; filename="29M.zip"'
|
||||
mail.attach(att2)
|
||||
|
||||
|
||||
try:
|
||||
# 连接smtp服务器,明文/SSL方式,根据使用的SMTP支持情况选择一种
|
||||
# 普通方式,通信过程不加密
|
||||
smtp = smtplib.SMTP(smtpHost, smtpPort)
|
||||
smtp.ehlo()
|
||||
smtp.login(username, password)
|
||||
|
||||
# # 纯粹的ssl加密方式,通信过程加密,邮件数据安全
|
||||
# # smtp = smtplib.SMTP(smtpHost, smtpPort)
|
||||
# smtp = smtplib.SMTP_SSL(smtpHost, sslPort)
|
||||
# smtp.ehlo()
|
||||
# smtp.login(username, password)
|
||||
|
||||
# 发送邮件
|
||||
smtp.sendmail(fromMail, toMail, mail.as_string())
|
||||
smtp.close()
|
||||
print('OK')
|
||||
|
||||
except Exception as e:
|
||||
print(e)
|
||||
```
|
||||
|
|
@ -0,0 +1,84 @@
|
|||
---
|
||||
title: SVN for Docker
|
||||
date: 2023-03-28 07:15:24.648
|
||||
updated: 2023-05-06 10:53:56.264
|
||||
url: /archives/svnfordocker
|
||||
categories:
|
||||
- Docker
|
||||
tags:
|
||||
- Docker
|
||||
---
|
||||
|
||||
# Docker搭建svn服务器
|
||||
|
||||
## svn的docker搭建方法
|
||||
|
||||
docker镜像为garethflowers/svn-server
|
||||
|
||||
启动命令
|
||||
|
||||
```csharp
|
||||
docker run --restart always --name svn -d -v /root/svn:/var/opt/svn -p 3690:3690 garethflowers/svn-server
|
||||
```
|
||||
|
||||
> /root/dockers/svn为宿主机的文件目录,/var/opt/svn为容器内的文件目录
|
||||
>
|
||||
> --restart always命令可以实现容器在宿主机开机时自启动
|
||||
>
|
||||
> -p 3690:3690表示将宿主机的3690端口映射到容器的3690端口,此端口为svn服务的默认端口,可以根据需要自行修改
|
||||
|
||||
## 创建svn仓库和账户
|
||||
|
||||
### 进入容器中进行配置
|
||||
|
||||
```bash
|
||||
docker exec -it svn /bin/sh
|
||||
```
|
||||
|
||||
### 创建名称为svn的资源仓库
|
||||
|
||||
```undefined
|
||||
svnadmin create svn
|
||||
```
|
||||
|
||||
创建成功后svn目录内应该包含以下文件:
|
||||
|
||||
```
|
||||
README.txt conf db format hooks locks
|
||||
```
|
||||
|
||||
### 资源仓库配置,修改svnserve.conf
|
||||
|
||||
```ruby
|
||||
anon-access = none # 匿名用户不可读写,也可设置为只读 read
|
||||
auth-access = write # 授权用户可写
|
||||
password-db = passwd # 密码文件路径,相对于当前目录
|
||||
authz-db = authz # 访问控制文件
|
||||
realm = /var/opt/svn/svn # 认证命名空间,会在认证提示界面显示,并作为凭证缓存的关键字,可以写仓库名称比如svn
|
||||
```
|
||||
|
||||
### 配置账号与密码,修改 passwd文件,格式为“账号 = 密码”
|
||||
|
||||
```csharp
|
||||
[users]
|
||||
# harry = harryssecret
|
||||
# sally = sallyssecret
|
||||
admin = 123456
|
||||
```
|
||||
|
||||
### 配置账户权限,修改 authz文件
|
||||
|
||||
```csharp
|
||||
[groups]
|
||||
owner = admin
|
||||
[/] # / 表示所有仓库
|
||||
admin = rw # 用户 admin 在所有仓库拥有读写权限
|
||||
[svn:/] # 表示以下用户在仓库 svn 的所有目录有相应权限
|
||||
@owner = rw # 表示 owner 组下的用户拥有读写权限
|
||||
```
|
||||
|
||||
## 拉取svn
|
||||
|
||||
```cpp
|
||||
svn://127.0.0.1/svn
|
||||
```
|
||||
|
|
@ -0,0 +1,107 @@
|
|||
---
|
||||
title: Ubuntu安装Docker
|
||||
date: 2021-07-14 15:31:47.099
|
||||
updated: 2023-04-21 00:31:57.714
|
||||
url: /archives/ubuntu安装docker
|
||||
categories:
|
||||
- Docker
|
||||
tags:
|
||||
- Docker
|
||||
---
|
||||
|
||||
# Docker官方文档
|
||||
https://docs.docker.com/engine/install/ubuntu/
|
||||
|
||||
|
||||
## 脚本安装
|
||||
```sh
|
||||
sudo curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
|
||||
```
|
||||
|
||||
## 使用命令行安装
|
||||
|
||||
`更新包`
|
||||
```sh
|
||||
sudo apt-get update
|
||||
```
|
||||
|
||||
`安装所需依赖`
|
||||
```sh
|
||||
sudo apt-get -y install apt-transport-https ca-certificates curl software-properties-common
|
||||
```
|
||||
|
||||
`安装 GPG 证书`
|
||||
```sh
|
||||
sudo curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
|
||||
```
|
||||
|
||||
`新增数据源`
|
||||
```sh
|
||||
sudo add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
|
||||
```
|
||||
|
||||
`更新并安装 Docker CE`
|
||||
```sh
|
||||
sudo apt-get update && apt-get install -y docker-ce
|
||||
```
|
||||
|
||||
`验证docker安装是否成功`
|
||||
```sh
|
||||
docker version
|
||||
```
|
||||
|
||||
`输出docker版本信息`
|
||||
```sh
|
||||
Client: Docker Engine - Community
|
||||
Version: 19.03.8
|
||||
API version: 1.40
|
||||
Go version: go1.12.17
|
||||
Git commit: afacb8b7f0
|
||||
Built: Wed Mar 11 01:25:46 2020
|
||||
OS/Arch: linux/amd64
|
||||
|
||||
······
|
||||
```
|
||||
|
||||
# 配置国内的镜像源
|
||||
|
||||
## 阿里云镜像加速
|
||||
在阿里云官网的帮助文档里搜索一下镜像加速
|
||||
通过修改 daemon 配置文件 /etc/docker/daemon.json 来使用加速器
|
||||
```sh
|
||||
sudo mkdir -p /etc/docker
|
||||
```
|
||||
括号内替换为你自己的镜像源就可以了
|
||||
```sh
|
||||
sudo mkdir -p /etc/docker
|
||||
sudo tee /etc/docker/daemon.json <<-'EOF'
|
||||
{
|
||||
"registry-mirrors": ["https://frcxiu9f.mirror.aliyuncs.com"]
|
||||
}
|
||||
EOF
|
||||
sudo systemctl daemon-reload
|
||||
sudo systemctl restart docker
|
||||
```
|
||||
|
||||
## 使用腾讯云镜像
|
||||
同样的步骤
|
||||
```
|
||||
vim /etc/docker/daemon.json
|
||||
```
|
||||
腾讯云的镜像源
|
||||
```
|
||||
{
|
||||
"registry-mirrors": [
|
||||
"https://mirror.ccs.tencentyun.com"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
使用任意一个,保存退出,重载配置文件
|
||||
```sh
|
||||
systemctl daemon-reload
|
||||
```
|
||||
重启Docker
|
||||
```sh
|
||||
systemctl restart docker
|
||||
```
|
||||
|
|
@ -0,0 +1,19 @@
|
|||
---
|
||||
title: Win10使用CMD关闭防火墙
|
||||
date: 2023-04-24 15:48:10.549
|
||||
updated: 2023-04-24 15:48:10.549
|
||||
url: /archives/win10-shi-yong-cmd-guan-bi-fang-huo-qiang
|
||||
categories:
|
||||
- Tools
|
||||
tags:
|
||||
---
|
||||
|
||||
关闭防火墙:
|
||||
```
|
||||
netsh advfirewall set allprofiles state off
|
||||
```
|
||||
|
||||
查看防火墙状态:
|
||||
```
|
||||
netsh advfirewall show allprofiles
|
||||
```
|
||||
|
|
@ -0,0 +1,61 @@
|
|||
---
|
||||
title: caddy入门
|
||||
date: 2022-05-30 18:10:12.683
|
||||
updated: 2022-12-06 18:22:15.116
|
||||
url: /archives/caddy入门
|
||||
categories:
|
||||
- Tools
|
||||
tags:
|
||||
- Tools
|
||||
---
|
||||
|
||||
下载
|
||||
https://github.com/caddyserver/caddy/releases
|
||||
|
||||
解压出来,例如:
|
||||
|
||||
```
|
||||
tar -zxvf caddy_2.5.1_linux_amd64.tar.gz
|
||||
```
|
||||
|
||||
caddy的二进制文件移动到/usr/local/bin目录下
|
||||
```
|
||||
mv caddy /usr/local/bin
|
||||
```
|
||||
caddy运行,通过caddy help查看常用命令
|
||||
```
|
||||
caddy
|
||||
```
|
||||
|
||||
创建/etc/caddy目录
|
||||
```
|
||||
mkdir -p /etc/caddy
|
||||
```
|
||||
创建Caddyfile文件
|
||||
```
|
||||
vim /etc/caddy/Caddyfile
|
||||
```
|
||||
|
||||
写入一个基本配置
|
||||
```
|
||||
www.yourdomain.com
|
||||
|
||||
encode gzip
|
||||
|
||||
reverse_proxy 127.0.0.1:8090
|
||||
```
|
||||
|
||||
重载配置文件
|
||||
```
|
||||
caddy reload
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,6 @@
|
|||
# 启动命令
|
||||
|
||||
```shell
|
||||
docker run -d --name=gogs -p 10022:22 -p 3000:3000 -v $PWD/.gogs:/data gogs/gogs
|
||||
```
|
||||
|
||||
|
|
@ -0,0 +1,87 @@
|
|||
|
||||
|
||||
# 注册Runner
|
||||
|
||||
```sh
|
||||
./act_runner-0.2.5-linux-amd64 --config config.yaml register
|
||||
```
|
||||
|
||||
运行runner
|
||||
|
||||
```sh
|
||||
nohup act_runner-0.2.5-linux-amd64 >/dev/null 2>&1 &
|
||||
```
|
||||
|
||||
runner配置,其中labels为:ubuntu-22.04:host 参照官方文档,这个可以用,意为在本地主机执行作业
|
||||
|
||||
```json
|
||||
{
|
||||
"WARNING": "This file is automatically generated by act-runner. Do not edit it manually unless you know what you are doing. Removing this file will cause act runner to re-register as a new runner.",
|
||||
"id": 11,
|
||||
"uuid": "3706a8fe-6d58-402a-bef1-7250497aea67",
|
||||
"name": "test_build",
|
||||
"token": "ceab31c3fbf94c7c5f03dcc9af3a87eb0f257370",
|
||||
"address": "http://43.154.19.134:3000/",
|
||||
"labels": [
|
||||
"ubuntu-22.04:host"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
# Docker方式注册Runner
|
||||
|
||||
```dockerfile
|
||||
docker run \
|
||||
-v $PWD/config.yaml:/config.yaml \
|
||||
-v $PWD/data:/data \
|
||||
-v /var/run/docker.sock:/var/run/docker.sock \
|
||||
-v /usr/local/hugo/blog:/usr/local/hugo/blog
|
||||
-v /var/www/blog:/var/www/blog
|
||||
-e CONFIG_FILE=/config.yaml \
|
||||
-e GITEA_INSTANCE_URL=<instance_url> \
|
||||
-e GITEA_RUNNER_REGISTRATION_TOKEN=<registration_token> \
|
||||
-e GITEA_RUNNER_NAME=<runner_name> \
|
||||
-e GITEA_RUNNER_LABELS=<runner_labels> \
|
||||
--name my_runner \
|
||||
-d gitea/act_runner:latest
|
||||
```
|
||||
|
||||
# yml工作流
|
||||
|
||||
```yml
|
||||
name: Blog CI & CD
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- master
|
||||
|
||||
env:
|
||||
# hugo生成site所在路径
|
||||
REPO_DIR: /usr/local/hugo/blog
|
||||
# 静态文件服务器代理的路径
|
||||
DEPLOYED_DIR: /var/www/blog
|
||||
|
||||
|
||||
jobs:
|
||||
build:
|
||||
name: Build_blog
|
||||
runs-on: ubuntu-22.04
|
||||
steps:
|
||||
- name: pull
|
||||
# pull远程仓库
|
||||
run: |
|
||||
git -C $REPO_DIR pull
|
||||
|
||||
deploy:
|
||||
name: Deploy blog
|
||||
runs-on: ubuntu-22.04
|
||||
needs: Build_blog
|
||||
steps:
|
||||
- name: Deploy
|
||||
# 指定hugo site路径,-D 忽略草稿,-d 生成文件放在指定路径下
|
||||
run: |
|
||||
hugo -s $REPO_DIR -D -d $DEPLOYED_DIR
|
||||
|
||||
```
|
||||
|
||||
|
|
@ -0,0 +1,91 @@
|
|||
---
|
||||
title: nginx配置带注释
|
||||
date: 2023-05-23 09:55:04.296
|
||||
updated: 2023-05-23 09:55:04.296
|
||||
url: /archives/nginx-pei-zhi-dai-zhu-shi
|
||||
categories:
|
||||
- Tools
|
||||
tags:
|
||||
- Tools
|
||||
---
|
||||
|
||||
server {
|
||||
# 监听 HTTP 和 HTTPS 端口
|
||||
listen 80;
|
||||
listen 443 ssl http2;
|
||||
|
||||
# 定义 server_name 这里是你的域名或ip,且支持正则匹配以及多规则匹配
|
||||
server_name example.com www.example.com;
|
||||
|
||||
# server_name *.example.com www.example.*;
|
||||
# 可匹配: 1.所有以example.com为后缀的域名 2.所有以www.example为前缀的域名
|
||||
|
||||
# server_name .example.com;
|
||||
# 可匹配所有以example.com为后缀的域名
|
||||
|
||||
# server_name ~^www\d+\.example\.com$;
|
||||
# 以 ~ 标记为正则表达式
|
||||
|
||||
# server_name ~^(www\.)?(?<domain>.+)$;
|
||||
# 允许将匹配到的 domain 值作为变量用于后面的Nginx配置
|
||||
|
||||
# server_name _;
|
||||
# 用于匹配所有域名。需要注意的是,通常作为最后一个server块的匹配规则存在,但不可只使用该配置项匹配
|
||||
|
||||
# 配置 SSL
|
||||
ssl_certificate /path/to/cert.crt;
|
||||
# SSL证书的路径,必须与 ssl_certificate_key 配合使用
|
||||
ssl_certificate_key /path/to/key.key;
|
||||
# SSL密钥文件的路径
|
||||
|
||||
# 定义 location 区域
|
||||
location / {
|
||||
# 不带参数的url匹配规则,将匹配所有的请求url,并使用下面的配置
|
||||
|
||||
# alias /data/w3/images/;
|
||||
# url别名,如果url为`/i/img.png`将被转换为`/data/w3/images/img.png`
|
||||
|
||||
root /data/w3/;
|
||||
# 直接决定url的根目录,`/i/img.png`将被转换为`/data/w3/i/images/img.png`
|
||||
|
||||
index index.html index.htm;
|
||||
# 默认文档名称,当客户端请求`www.example.com`时,将默认返回`/data/w3/index.html`文件或`/data/w3/index.htm`文件
|
||||
# 如果没有文件匹配则根据其他规则处理
|
||||
|
||||
try_files $uri $uri/ /index.html;
|
||||
# 在文件系统中查询文件
|
||||
# 如果$url对应的文件存在则直接返回该文件;如果不存在则返回$url/下的index.html文件;否则返回根目录下的/index.html文件
|
||||
|
||||
# 开启反向代理
|
||||
proxy_pass http://backend;
|
||||
# 将请求转发至http://backend服务器处理,并返回代理服务器的响应
|
||||
|
||||
# 定义反向代理头部
|
||||
proxy_set_header X-Real-IP $remote_addr;
|
||||
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||||
proxy_set_header Host $http_host;
|
||||
# 定义代理请求头,可以在这里对请求头做校验工作
|
||||
}
|
||||
|
||||
# 配置 HTTPS 重定向
|
||||
if ($scheme != "https") {
|
||||
return 301 https://$server_name$request_uri;
|
||||
}
|
||||
# $scheme以变量形式存储请求是否为SSL,更多变量可以查看 http://nginx.org/en/docs/http/ngx_http_core_module.html#variables
|
||||
|
||||
# 定义 error_page 区域
|
||||
error_page 404 /404.html;
|
||||
# 当出现404错误时,跳转至404.html
|
||||
|
||||
location = /404.html {
|
||||
internal;
|
||||
}
|
||||
# 表示404页面只有当出现404错误时才会出现,并且由Nginx进行内部跳转,即使修改url也无法进入404页面
|
||||
}
|
||||
|
||||
server {
|
||||
# 你可以使用多个server块来匹配多个host
|
||||
...
|
||||
}
|
||||
|
||||
for https://juejin.cn/post/7235908012673384485
|
||||
|
|
@ -0,0 +1,48 @@
|
|||
---
|
||||
title: pip镜像源
|
||||
date: 2023-05-13 10:30:56.581
|
||||
updated: 2023-05-13 10:32:36.714
|
||||
url: /archives/pip-jing-xiang-yuan
|
||||
categories:
|
||||
- Tools
|
||||
tags:
|
||||
- Tools
|
||||
---
|
||||
|
||||
常用的国内源:
|
||||
|
||||
清华:
|
||||
```
|
||||
https://pypi.tuna.tsinghua.edu.cn/simple/
|
||||
```
|
||||
阿里云:
|
||||
```
|
||||
http://mirrors.aliyun.com/pypi/simple/
|
||||
```
|
||||
中国科技大学 :
|
||||
```
|
||||
https://pypi.mirrors.ustc.edu.cn/simple/
|
||||
```
|
||||
华中科技大学:
|
||||
```
|
||||
http://pypi.hustunique.com/
|
||||
```
|
||||
豆瓣:
|
||||
```
|
||||
http://pypi.douban.com/simple/
|
||||
```
|
||||
|
||||
|
||||
|
||||
临时使用阿里源
|
||||
|
||||
```
|
||||
pip install packageName -i http://mirrors.aliyun.com/pypi/simple/
|
||||
```
|
||||
|
||||
pip cmd 命令行设置全局镜像源: 阿里源
|
||||
|
||||
```
|
||||
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
|
||||
```
|
||||
|
||||
|
|
@ -0,0 +1,110 @@
|
|||
---
|
||||
title: win10安装JDK配置环境变量
|
||||
date: 2023-03-20 16:44:32.706
|
||||
updated: 2023-03-25 19:23:58.287
|
||||
url: /archives/jdkforwin10
|
||||
categories:
|
||||
- Java
|
||||
tags:
|
||||
- Java
|
||||
---
|
||||
|
||||
# win10安装JDK配置环境变量
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
## 安装
|
||||
|
||||
保持默认
|
||||
|
||||

|
||||
|
||||
> 可以选择更改安装路径
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
## 配置环境变量
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
选择高级系统设置
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
在系统变量点击新建
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
## JAVA_HOME
|
||||
|
||||
`JAVA_HOME`
|
||||
|
||||
`C:\Program Files\Java\jdk1.8.0_241`
|
||||
|
||||
其实就是jdk安装目录的路径
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
## CLASSPATH
|
||||
|
||||
再次新建系统变量
|
||||
|
||||
`CLASSPATH`
|
||||
|
||||
`.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar`
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
## PATH
|
||||
|
||||
找到系统变量里的path变量,path里新建
|
||||
|
||||
`%JAVA_HOME%\bin`
|
||||
|
||||

|
||||
|
||||
## 测试
|
||||
|
||||
cmd窗口分别输入java 、javac、 java -version
|
||||
|
|
@ -0,0 +1,152 @@
|
|||
---
|
||||
title: win10安装Mysql5.7
|
||||
date: 2023-04-15 18:14:38.026
|
||||
updated: 2023-04-26 19:32:26.938
|
||||
url: /archives/mysql57-for-win10
|
||||
categories:
|
||||
- 数据库
|
||||
tags:
|
||||
- DB
|
||||
---
|
||||
|
||||
# win10安装Mysql5.7
|
||||
|
||||
> 环境:windows10 + Mysql5.7.33
|
||||
|
||||
## 下载Mysql安装包
|
||||
|
||||
下载地址:https://downloads.mysql.com/archives/community/
|
||||
|
||||
## 解压Mysql包
|
||||
|
||||
本次解压的目录是:D:\mysql-5.7.33-winx64
|
||||
|
||||
如果是其它路径,记一下解压路径
|
||||
|
||||
在目录里手动 **创建一个data文件夹** ,这个是存放数据库数据存放目录
|
||||
|
||||
然后 **创建一个my.ini文件** ,这个是配置文件,可以自定义配置
|
||||
|
||||

|
||||
|
||||
|
||||
下面给出ini一个示例,其中basedir和datadir根据实际安装目录替换一下
|
||||
|
||||
```ini
|
||||
[mysql]
|
||||
#设置mysql客户端默认字符集
|
||||
default-character-set=utf8
|
||||
[mysqld]
|
||||
#设置端口
|
||||
port=3306
|
||||
#设置mysql安装目录
|
||||
basedir=D:\mysql-5.7.33-winx64
|
||||
#设置数据库数据存放目录
|
||||
datadir=D:\mysql-5.7.33-winx64\data
|
||||
#允许最大连接数
|
||||
max_connections=180
|
||||
#服务端字符集
|
||||
character-set-server=utf8
|
||||
#创建新表时默认存储引擎
|
||||
default-storage-engine=INNODB
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 配置环境变量
|
||||
|
||||
可以不配置,进入到bin目录执行命令也是可以的
|
||||
|
||||
`MYSQL_HOME`
|
||||
|
||||
`D:\mysql-5.7.33-winx64\bin`
|
||||
|
||||
## 安装Mysql
|
||||
|
||||
**需要使用管理员权限打开CMD!**
|
||||
|
||||
cmd.exe在C:\Windows\SysWOW64目录下,找到cmd.exe鼠标右键使用管理员权限打开cmd
|
||||
|
||||
**在mysql的bin目录下执行安装命令**
|
||||
|
||||
```sh
|
||||
mysqld install
|
||||
```
|
||||

|
||||
|
||||
|
||||
**执行初始化命令**
|
||||
|
||||
加--console目的是为了输入默认密码,后面这个密码会更改
|
||||
|
||||
```sh
|
||||
mysqld --initialize --console
|
||||
```
|
||||

|
||||
|
||||
**启动Mysql服务**
|
||||
|
||||
```sh
|
||||
net start mysql
|
||||
```
|
||||

|
||||
|
||||
**登录Mysql**
|
||||
|
||||
使用上面的默认密码登录Mysql
|
||||
|
||||
```
|
||||
mysql -u root -p
|
||||
```
|
||||
|
||||
**修改密码**
|
||||
|
||||
可以把123456替换为别的密码,注意要有单引号
|
||||
|
||||
```
|
||||
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456';
|
||||
```
|
||||

|
||||
|
||||
`exit` 命令退出
|
||||
|
||||
**使用客户端测试连接**
|
||||

|
||||
|
||||
## 修改root密码(忘记密码)
|
||||
有一次我打开电脑后使用DOS登录Mysql报了下面这个错误
|
||||
```
|
||||
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)
|
||||
```
|
||||
应该是密码有问题,但是我不清楚为什么有问题,大概率密码错误?或者我之前的密码不是这个,我记错了?
|
||||
说一下我的解决办法
|
||||
|
||||
### 解决办法
|
||||
在win系统中停止Mysql服务
|
||||
|
||||
打开DOS窗口,转到mysql\bin目录
|
||||
|
||||
输入mysqld --skip-grant-tables 回车。--skip-grant-tables 的意思是启动MySQL服务的时候跳过权限表认证。
|
||||
```
|
||||
mysqld --skip-grant-tables
|
||||
```
|
||||
|
||||
输入mysql回车,如果成功,将出现MySQL提示符
|
||||
|
||||
进入数据库
|
||||
```
|
||||
use mysql;
|
||||
```
|
||||
这里要使用下面这个命令刷一下权限,不然执行修改密码的命令会提示无权限
|
||||
```
|
||||
flush privileges;
|
||||
```
|
||||
|
||||
然后修改密码
|
||||
```
|
||||
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456';
|
||||
```
|
||||
然后重启数据库,打开新的DOS窗口使用新密码就可以登录了
|
||||
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,55 @@
|
|||
---
|
||||
title: 开启Mysql数据库日志
|
||||
date: 2023-04-19 15:43:58.709
|
||||
updated: 2023-04-19 17:20:44.772
|
||||
url: /archives/open-mysql-log
|
||||
categories:
|
||||
- 数据库
|
||||
tags:
|
||||
- DB
|
||||
---
|
||||
|
||||
想查看数据库执行SQL的记录,可以开启日志,默认是OFF状态,开启后长时间输出日志会占用存储空间,不需要时记得要关闭日志
|
||||
|
||||
## 临时开启log
|
||||
|
||||
**在Mysql中执行**
|
||||
查看是否已经开启,并且会输出日志默认存放路径
|
||||
|
||||
```sql
|
||||
SHOW VARIABLES LIKE "general_log%";
|
||||
```
|
||||
|
||||
开启实时日志输出
|
||||
|
||||
```sql
|
||||
SET GLOBAL general_log = 'ON';
|
||||
```
|
||||
|
||||
通过tail命令实时查看Mysql日志
|
||||
|
||||
**这种方式在Mysql重启后会失效**
|
||||
|
||||
## 永久开启log
|
||||
|
||||
编辑my.cnf文件
|
||||
|
||||
```sh
|
||||
vim /etc/my.cnf
|
||||
```
|
||||
|
||||
加入下面两行
|
||||
|
||||
```
|
||||
general_log = 1
|
||||
general_log_file = /var/log/mysql/general_sql.log
|
||||
```
|
||||
|
||||
重启mysql生效
|
||||
|
||||
```sh
|
||||
service mysqld restart
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,30 @@
|
|||
---
|
||||
title: 开启root远程登录Linux
|
||||
date: 2021-04-14 11:38:32.0
|
||||
updated: 2022-09-13 09:40:06.804
|
||||
url: /archives/permitrootlogin
|
||||
categories:
|
||||
- Linux
|
||||
tags:
|
||||
- Linux
|
||||
---
|
||||
|
||||
设置root密码
|
||||
```
|
||||
sudo passwd
|
||||
```
|
||||
修改配置文件**sshd_config**
|
||||
```
|
||||
sudo vim /etc/ssh/sshd_config
|
||||
```
|
||||
|
||||
修改这两条并保存
|
||||
```
|
||||
PermitRootLogin yes
|
||||
PasswordAuthentication yes
|
||||
```
|
||||
重载sshd
|
||||
```
|
||||
sudo systemctl reload sshd
|
||||
```
|
||||
重新连接即可使用root权限远程连接
|
||||
|
|
@ -0,0 +1,825 @@
|
|||
---
|
||||
title: 数据库基础SQL查询
|
||||
date: 2023-04-27 11:38:38.451
|
||||
updated: 2023-04-27 11:38:38.451
|
||||
url: /archives/query
|
||||
categories:
|
||||
- 数据库
|
||||
tags:
|
||||
- DB
|
||||
---
|
||||
|
||||
> 数据查询语言DQL:Data query language
|
||||
|
||||
## 基础查询
|
||||
|
||||
> 注意:每个SQL语句后加上英文符号`;` 养成良好习惯,避免不必要问题
|
||||
>
|
||||
> 建议1:SQL例如SELECT、FROM、WHERE等关键字使用大写
|
||||
>
|
||||
> 建议2:所有的例如逗号、括号、引号等等符号全部使用英文符号,避免不必要问题
|
||||
|
||||
- 查询所有列
|
||||
|
||||
```sql
|
||||
select * from tableName;
|
||||
```
|
||||
|
||||
- 查询指定列
|
||||
|
||||
```sql
|
||||
select columnName1,columnName2 from tableName;
|
||||
```
|
||||
|
||||
- 列数值计算(在列名后直接跟上运算)
|
||||
|
||||
```sql
|
||||
select columnName1*12,columnName2 from tableName;
|
||||
```
|
||||
|
||||
- 列字符串拼接(多列拼接作为一列显示)
|
||||
|
||||
```sql
|
||||
-- 注意:Oracle的字符串只能使用单引号
|
||||
select columnName1||' '||columnName2 from tableName;
|
||||
```
|
||||
|
||||
- 列别名
|
||||
|
||||
```sql
|
||||
select columnName1 As alias1,columnName2 As alias2 from tableName;
|
||||
```
|
||||
|
||||
```sql
|
||||
-- As也可以省略不写
|
||||
select columnName1 alias1,columnName2 alias2 from tableName;
|
||||
```
|
||||
|
||||
- 去除重复记录
|
||||
|
||||
```sql
|
||||
-- 在列名前使用关键字 DISTINCT 去除这列重复的记录
|
||||
select DISTINCT columnName1 from tableName;
|
||||
```
|
||||
|
||||
### 精准查询
|
||||
|
||||
> 条件查询使用where子句
|
||||
|
||||
- 基本语法
|
||||
|
||||
```sql
|
||||
select columnName1,columnName2 from tableName where 条件表达式(可以是一个条件也可以是多个条件);
|
||||
```
|
||||
|
||||
- 精准查询
|
||||
|
||||
```sql
|
||||
-- 比较运算符
|
||||
-- 注释:在SQL的一些版本中,<>可被写成!=
|
||||
-- 当比较值为数值时不需要引号
|
||||
-- 当比较值为字符串时必须使用单引号或者双引号
|
||||
= > >= < <= != <> ^=
|
||||
```
|
||||
|
||||
示例
|
||||
|
||||
```sql
|
||||
-- 以工资salary大于一万作为条件执行查询
|
||||
select salary from tableName where salary>10000;
|
||||
```
|
||||
|
||||
- 范围查询 BETWEEN 下边界 AND 上边界
|
||||
|
||||
```sql
|
||||
-- 以工资salary介于一万和两万之间作为条件执行查询
|
||||
select salary from tableName where salary between 10000 and 20000;
|
||||
```
|
||||
|
||||
- 根据多个值查询 IN(值1, 值2, ... 值N)
|
||||
|
||||
```sql
|
||||
-- 以姓名username'张三','李四','王五'作为条件执行查询
|
||||
select username from tableName where salary in('张三','李四','王五');
|
||||
```
|
||||
|
||||
- 逻辑运算符
|
||||
|
||||
NOT 表示否定 AND 表示并且 OR 表示或者 优先级 NOT > AND > OR
|
||||
|
||||
逻辑运算符 not and or 优先级为 not>and>or
|
||||
|
||||
建议:复杂逻辑运算可以加括号避免干扰
|
||||
|
||||
```sql
|
||||
-- 以工资等于一万或者两万作为条件执行查询
|
||||
select username from tableName where salary=10000 or salary=20000;
|
||||
```
|
||||
|
||||
- 空值比较
|
||||
|
||||
IS NULL 表示为空 IS NOT NULL 表示不为空
|
||||
|
||||
```sql
|
||||
-- 以email为空作为条件执行查询
|
||||
select email from tableName where email is null;
|
||||
```
|
||||
|
||||
### 模糊查询
|
||||
|
||||
- like查询
|
||||
|
||||
两个简单的通配符:`%` 和 `_`
|
||||
|
||||
`%` 任意匹配,下划线 `_` 匹配一个任意字符
|
||||
|
||||
注意:Mysql数据库支持正则表达式,但是需要使用`REGEXP `关键字指定正则表达式的字符匹配模式
|
||||
|
||||
```sql
|
||||
-- %a% a% %a 含义分别为包含字符a,以字符a开头,以字符a结尾,以第一个举例
|
||||
select name from tableName where name like '%a%';
|
||||
```
|
||||
|
||||
### 伪列
|
||||
|
||||
- 关键字 ROWNUM
|
||||
|
||||
**注意:**并非所有的数据库系统都支持 SELECT TOP 语句。
|
||||
|
||||
Oracle 可以使用 ROWNUM 来选取
|
||||
|
||||
MySQL 可以使用 LIMIT 语句来选取指定的条数数据,
|
||||
|
||||
```sql
|
||||
-- Oracle语法
|
||||
-- 注意运算符只支持 < <=,不支持 > >= =,其中 =1 是例外支持
|
||||
select columnName from tableName where rownum <= 10 ; -- 选取前10条数据
|
||||
```
|
||||
|
||||
```sql
|
||||
-- Mysql语法
|
||||
select columnName from tableName LIMIT 10; -- 选取前10条数据
|
||||
```
|
||||
|
||||
|
||||
### 排序查询
|
||||
|
||||
排序中的空值需要扩展一下:
|
||||
|
||||
不同的数据库中的null在排序中的默认值是不同的
|
||||
|
||||
- 在`PostgreSQL`中,null值默认最大
|
||||
- 在`Oracle`中,null值默认最大
|
||||
- 在`Mysql`和`SQLServer`中,null值默认最小
|
||||
|
||||
因此建议使用 **nulls last** 和 **nulls first** 来指定这些null值排在前面还是后面,另外该关键字只能搭配order by来使用。
|
||||
|
||||
`ORDER BY` 子句
|
||||
|
||||
子句书写顺序 `SELECT -> FROM -> WHERE -> ORDER BY`
|
||||
|
||||
子句执行顺序 `FROM -> WHERE -> SELECT -> ORDER BY`
|
||||
|
||||
```sql
|
||||
-- 默认就是升序排列
|
||||
select salary from tableName where salary > 2000 order by;
|
||||
|
||||
-- 多排列,先按name升序,再按salary降序
|
||||
select name,salary from tableName order by name asc, salary desc;
|
||||
```
|
||||
|
||||
```sql
|
||||
-- 空值排在最后
|
||||
select email from tableName order by email desc nulls last;
|
||||
```
|
||||
|
||||
### 分组查询
|
||||
|
||||
#### 分组函数
|
||||
|
||||
- 分组函数又称为统计函数,用于将查询结果分成几个组,出现与 SELECT 的列和 HAVING 子句中
|
||||
- `COUNT` 统计查询出的结果数量
|
||||
- `AVG` 求查询结果中某列的平均值
|
||||
- `MAX` 求查询结果中某列的最大值
|
||||
- `MIN` 求查询结果中某列的最小值
|
||||
- `SUM` 求查询结果中某列的总和
|
||||
|
||||
>分组函数 AVG、SUM 只能统计数值,MAX、MIN 可以统计字符串
|
||||
>
|
||||
>分组函数 COUNT 统计所有类型,不统计空值
|
||||
>
|
||||
>COUNT(*) 和 COUNT(1) 统计所有列,返回行数
|
||||
>
|
||||
>COUNT(字段名) 统计某字段
|
||||
|
||||
```sql
|
||||
-- 统计表中user_id列不为空且不重复的数量
|
||||
select count(distinct user_id) FROM tableName;
|
||||
```
|
||||
|
||||
需要注意的是分组函数不能跟普通的列混合,例如下面这个错误例子:
|
||||
|
||||
```sql
|
||||
select count(distinct user_id),name FROM tableName;
|
||||
```
|
||||
|
||||
#### 分组查询
|
||||
|
||||
- `GROUP BY` 子句
|
||||
|
||||
- 子句书写顺序 `SELECT -> FROM -> WHERE -> GROUP BY -> ORDER BY`
|
||||
|
||||
- 子句执行顺序 `FROM -> WHERE -> GROUP BY -> SELECT -> ORDER BY`
|
||||
|
||||
- GROUP BY 子句将查询结果细分为更小的组,GROUP BY 子句后只能跟字段名
|
||||
|
||||
- 没有 GROUP BY 子句时 SELECT 子句可以出现分组函数,但不能同时出现其它字段
|
||||
|
||||
- 有 GROUP BY 子句时 SELECT 子句只允许出现分组函数和分组字段
|
||||
|
||||
- 在 GROUP BY 子句中若出现多列时是按照多列组合值进行分组
|
||||
```sql
|
||||
-- 分组查询 关键字 group by + 分组的列
|
||||
-- 执行顺序 from->where->group by->_func->select->order by
|
||||
-- 分部门查询每个dept_id的最高salary和平均salary
|
||||
select dept_id,max(salary),avg(salary)
|
||||
from s_emp
|
||||
group by dept_id;
|
||||
|
||||
-- 分部门查询每个dept_id每个title的最高工资、部门id、岗位
|
||||
select max(salary) as 最高工资,dept_id as 部门id,title as 岗位
|
||||
from s_emp
|
||||
group by dept_id,title;-- 分组可以跟多列 先按第一列分组再按第二列分组
|
||||
|
||||
```
|
||||
|
||||
#### 分组条件过滤
|
||||
|
||||
- `having` 子句
|
||||
- 子句书写顺序 `SELECT -> FROM -> WHERE -> GROUP BY -> HAVING -> ORDER BY`
|
||||
- 子句执行顺序 `FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY`
|
||||
- HAVING 子句用来对 GROUP BY 的结果集进行条件过滤,只允许出现分组函数和分组字段
|
||||
- WHERE 子句中不允许出现分组函数,HAVING 子句不允许使用列的别名
|
||||
|
||||
```sql
|
||||
-- 分组过滤 having 子句用于对group by 子句的过滤
|
||||
-- 书写顺序 select->from->where->group by->order by
|
||||
-- 执行顺序 from->where->group by->分组函数->having->select->order by
|
||||
-- 从员工表中查询出平均工资大于1500的部门编号、平均工资、最高工资,并且按照部门编号升序排列
|
||||
-- select dept_id,avg(salary),max(salary) from s_emp where avg(salary)>1500
|
||||
group by dept_id; --报错 where后不能使用分组函数(执行顺序)
|
||||
select dept_id,avg(salary),max(salary)
|
||||
from s_emp
|
||||
group by dept_id
|
||||
having avg(salary)>1500
|
||||
order by dept_id asc;
|
||||
-- having 子句中跟分组字段(dept_id) 则与分组字段在where子句中作用是一样的
|
||||
-- 从员工表中查询出部门编号大于20的部门编号、平均工资、最高工资
|
||||
-- 先分组再按照分组字段对分组结果过滤
|
||||
select dept_id,avg(salary),max(salary)
|
||||
from s_emp
|
||||
group by dept_id
|
||||
having dept_id>20;
|
||||
-- 先按照分组字段进行过滤 再在过滤结果上进行分组
|
||||
select dept_id,avg(salary),max(salary)
|
||||
from s_emp
|
||||
where dept_id>20
|
||||
group by dept_id;
|
||||
```
|
||||
|
||||
### 集合操作
|
||||
|
||||

|
||||
|
||||
#### 并集
|
||||
|
||||
- `UNION` 返回几个查询结果的全部内容,但不显示重复记录
|
||||
|
||||
- `UNION All` 返回几个查询结果的全部内容,重复记录也会显示
|
||||
|
||||
```
|
||||
-- 并集 union 返回几个查询结果的全部内容 但不显示重复记录 union all 显示重复记录
|
||||
select id,first_name from s_emp where id<8;--1 2 3 4 5 6 7
|
||||
select id,first_name from s_emp where id between 6 and 10;--6 7 8 9 10
|
||||
-- 1 2 3 4 5 6 7 8 9 10
|
||||
select id,first_name from s_emp where id<8
|
||||
union
|
||||
select id,first_name from s_emp where id between 6 and 10;
|
||||
-- 1 2 3 4 5 6 7 6 7 8 9 10
|
||||
select id,first_name from s_emp where id<8
|
||||
union all
|
||||
select id,first_name from s_emp where id between 6 and 10;
|
||||
```
|
||||
|
||||
|
||||
#### 差集
|
||||
|
||||
- `MINUS` 返回几个查询结果的不同部分
|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
--差集minus 返回几个查询结果的不同部分 从第一个集合中去掉第二个集合中的部分
|
||||
--1 2 3 4 5
|
||||
select id,first_name from s_emp where id<8
|
||||
minus
|
||||
select id,first_name from s_emp where id between 6 and 10;
|
||||
```
|
||||
|
||||
#### 交集
|
||||
|
||||
- `INTERSECT` 返回几个查询结果的相同部分
|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
-- 交集 intersect 取两个集合一样的行
|
||||
-- 6 7
|
||||
select id,first_name from s_emp where id<8
|
||||
intersect
|
||||
select id,first_name from s_emp where id between 6 and 10;
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 单行函数
|
||||
|
||||
#### 字符函数
|
||||
|
||||
Oracle 的 SELECT SQL 语法要求一定要有数据源,不需要数据源可以使用虚拟表 dual
|
||||
|
||||
- `UPPER` 转换成大写
|
||||
|
||||
- `LOWER` 转换成小写
|
||||
|
||||
- `INITCAP` 首字母大写
|
||||
|
||||
- `CONCAT(字符串1, 字符串2)` 字符串的连接
|
||||
|
||||
- `SUBSTR(字符串, 下标, 截取长度)` 字符串的截取,下标从1开始
|
||||
|
||||
- `LENGTH` 获取字符串的长度
|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
--虚拟表 dual
|
||||
select 1+2 from dual;
|
||||
|
||||
--单行函数
|
||||
--字符串函数
|
||||
-- 将所有的职位转换成大写输出
|
||||
select distinct upper(title) from s_emp; --转大写
|
||||
select distinct lower(title) from s_emp; --转小写
|
||||
select initcap('mark') from dual;--首字母转大写
|
||||
select substr('51testing',1, 6) from dual;--字符串截取substr(字符串, 起始位置, 长度) 字符串下标从1开始
|
||||
select substr('51testing',0,4),substr('51testing',-3, 5),substr('51testing', -3) from dual; -- 末尾的下标 -1
|
||||
select concat('hello','oracle') from dual; --字符串拼接
|
||||
select length('51testing') from dual; --字符串长度
|
||||
--忽略大小写
|
||||
--HenRy
|
||||
select * from s_emp where upper(first_name)='HENRY';
|
||||
select * from s_emp where lower(first_name)='henry';
|
||||
```
|
||||
|
||||
#### 通用函数
|
||||
|
||||
- `NVL(列名,'字符串')` 将列中的空值替换成字符串
|
||||
|
||||
- `NVL(列名, 数字)` 将列中的空值替换成数值
|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
--通用函数 NVL(列名,'字符串')NVL(列名,数值) 列名中值为空的使用后面的数据补齐
|
||||
select salary, salary+salary*commission_pct/100 from s_emp;
|
||||
select salary, salary+salary*nvl(commission_pct,0)/100 from s_emp;
|
||||
```
|
||||
|
||||
|
||||
#### 数值函数
|
||||
|
||||
- `ROUND` 四舍五入
|
||||
|
||||
- `TRUNC` 截取,不进行四舍五入
|
||||
|
||||
- `MOD` 取余
|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
--round(字段,数值)四舍五入 数值可以不传,表示取整 为正,表示小数点后保留几位 为负,表示小数点前向前取整取几位
|
||||
select round(1234.567),round(1234.567,1),round(1234.567,-2) from dual; --1235 1234.6 1200
|
||||
|
||||
--trunc(字段,数值) 截位
|
||||
select trunc(1234.567), trunc(1234.567,1),trunc(1234.567,-2) from dual; --1234 1234.5 1200
|
||||
|
||||
--mod(数值1,数值2) 取余
|
||||
select mod(5,2) from dual; --1
|
||||
```
|
||||
|
||||
#### 转换函数
|
||||
|
||||
- `TO_NUMBER(字符串)` 将一个数值字符串转换成数值
|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
-- 转换函数
|
||||
-- to_number(字符串)
|
||||
select to_number('1234.567') from dual;
|
||||
```
|
||||
|
||||
- `TO_CHAR(数值,'格式')` 数值转换成字符串
|
||||
|
||||
> **格式**
|
||||
> 0:显示数字,如位数不足,则用0补齐。9:显示数字,并忽略前面0。逗号是千分号。L表示本地货币符号,$表示美元符号。
|
||||
> 格式最前面加FM可以删除9占位所产生的多余空格或0
|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
--to_char(数值,'格式') --占位符 0 显示数字如果位数不足使用0补齐 9表示占位 如果位数不足,用0补齐,并且忽略小数点前面的0
|
||||
select to_char(1234567.5678,'99,999,999.999'),to_char(1234567.5678,'00,000,000.000') from dual; -- 逗号表示千分位
|
||||
--FM 可以删除 9 占位 小数点后的占位 对格式0占位无效的
|
||||
--L表示本地货币 $表示美元
|
||||
select to_char(1234567.5678, 'FML99,999,999.999999999'),to_char(1234567.5678, 'FML00,000,000.000000000') from dual;
|
||||
```
|
||||
|
||||
- `TO_CHAR(日期,'格式')` 日期转换成字符串
|
||||
|
||||
> **日期格式模型元素**
|
||||
> YYYY 四位数字的年 YY 两位数字的年
|
||||
> MM 两位数字的月 MON 月份的缩写 MONTH 月份的全称
|
||||
> DD 一个月的第几天 DDD 一年的第几天
|
||||
> DAY 星期几的全称 DY 星期几的缩写 D 星期几的数字表示(星期天为1,星期六为7)
|
||||
> HH 12小时制 HH24 24小时制 MI 分钟 SS 秒 AM 上午 PM 下午
|
||||
> **日期的文字方式显示结果和日期语言相关**
|
||||
> ALTER SESSION SET NLS_DATE_LANGUAGE="语言";
|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
-- to_char(日期,'格式')
|
||||
select start_date from s_emp;
|
||||
alter session set nls_date_language='simplified chinese';--- 设置日期显示的语言格式
|
||||
alter session set nls_date_language='english';--- 设置日期显示的语言格式
|
||||
|
||||
--YYYY四位数字年 MM两位数字月DD表示一个月第几天 HH时MI分SS秒 HH24 24小时制
|
||||
select to_char(start_date, 'YYYY/MM/DD HH24:MI:SS') from s_emp;
|
||||
--MON 表示月份的简写 DD 表示两位天 YY 表示两位年
|
||||
select to_char(sysdate, 'mon-dd-yy') from dual;
|
||||
--ddd 表示是一年的第几天 day 表示星期几 dy 星期几的简写 d 表示一周的第几天 会将星期日作为第一天
|
||||
select to_char(sysdate, 'yyyy.ddd'),--ddd 表示是一年的第几天
|
||||
to_char(sysdate,'day'),--day 表示星期几
|
||||
to_char(sysdate, 'dy'),--dy 星期几的简写
|
||||
to_char(sysdate,'d'),--d 表示一周的第几天 会将星期日作为第一天
|
||||
to_char(sysdate,'yyyy/mm/dd hh:mi:ss pm'), --pm 展示上午下午
|
||||
to_char(sysdate, 'mon-dd-yy'), -- MON 表示月份的简写 DD 表示两位天 YY 表示两位年
|
||||
to_char(sysdate, 'month') --月份全称
|
||||
from dual;
|
||||
```
|
||||
|
||||
- `TO_DATE(字符串,'格式')` 将一个日期字符串转换成日期,日期可以进行加减,不能进行乘除
|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
select to_date('2023/3/17','yyyy/mm/dd')-30 from dual;--返回计算后的日期
|
||||
```
|
||||
|
||||
==**练习**==
|
||||
|
||||
```plsql
|
||||
-- 从订单表s_ord中查询出编号sales_rep_id为11销售代表的每个订单金额total.
|
||||
-- 金额以美元显示,整数7位,小数两位,小数不足的位数以0填充,有千分位
|
||||
SELECT total, TO_CHAR(total, '$9,999,999.00'), TO_CHAR(total, 'FM$9,999,999.00')
|
||||
FROM s_ord
|
||||
WHERE sales_rep_id = 11;
|
||||
|
||||
-- 从员工表s_emp中,查询出1991年入职的员工姓名和入职日期,输出日期格式为数字形式的年/月,其中年为4位数字。
|
||||
SELECT first_name||' '||last_name 姓名, TO_CHAR(start_date, 'YYYY/MM') 入职日期
|
||||
FROM s_emp
|
||||
WHERE TO_CHAR(start_date, 'YYYY') = '1991';
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 多表查询
|
||||
|
||||
#### 数据库范式
|
||||
|
||||
- 第一范式:要求表中无重复的列
|
||||
|
||||
- 第二范式:需满足第一范式,要求表中无重复的行
|
||||
|
||||
- 第三范式:需满足第二范式,要求一个数据库表中不包含已在其它表中已包含的非主关键字信息
|
||||
|
||||
`Primary Key` 主键 用来唯一标识表中的每一行数据
|
||||
|
||||
`Foreign Key` 外键 表与表之间的关联关系
|
||||
|
||||
|
||||
#### 等值连接
|
||||
|
||||
- 判断某两列是否相等,从而建立连接,通常是主键与外键进行连接
|
||||
|
||||
- 采用表名加上列名,来标示列名,从而防止出现列名相同的情况
|
||||
|
||||
- 表可以起别名,表的别名前不能加AS关键字。
|
||||
|
||||
- 一旦给表起了别名,标识列时只能通过表的别名标识,而不能通过原名标识。
|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
-- 多表查询
|
||||
--等值连接
|
||||
-- 查询所有员工的名字、职位和部门名称
|
||||
-- 找到数据源 s_emp s_dept
|
||||
-- 找到关联关系 s_emp dept_id 和s_dept id s_emp dept_id = s_dept id
|
||||
-- 找到我们要查询的列
|
||||
|
||||
-- 可以给表起别名 通过表名.的方式使用 如果表有别名 就不再使用原先表名
|
||||
-- 列名有冲突的时候使用表名.列名的方式区分 表名 的别名不使用 as
|
||||
select * from s_emp;
|
||||
select * from s_dept;
|
||||
select * from s_emp,s_dept;--笛卡儿积 集合A 1 2 3 集合B a b c <1,a><1,b><1,c><2,a><2,b><2,c><3,a><3,b><3,c>
|
||||
select * from s_emp,s_dept where s_emp.dept_id=s_dept.id; -- 关联关系
|
||||
select first_name, title, name from s_emp,s_dept where s_emp.dept_id=s_dept.id;--找到查询的列
|
||||
|
||||
-- 查询部门是41的员工的名字、职位和部门名称
|
||||
-- 找到数据源 s_emp s_dept
|
||||
-- 对应关系 s_emp.dept_id=s_dept.id
|
||||
-- 找列
|
||||
select a.id,a.first_name,a.title,b.name,b.id
|
||||
from s_emp a,s_dept b
|
||||
where a.dept_id=b.id and a.dept_id=41;
|
||||
|
||||
```
|
||||
|
||||
#### 内连接
|
||||
|
||||
- `INNER JOIN` 内连接
|
||||
|
||||
用INNER JOIN连接表,关联条件写在ON后面,INNER可省略
|
||||
|
||||
从多个表中返回满足关联条件的所有行
|
||||
|
||||

|
||||
|
||||
**示例**
|
||||
```plsql
|
||||
--内连接 表1inner join 表2 on 条件 其中inner可以省略
|
||||
-- 查询部门为41的所有员工的名字、职位、部门名称
|
||||
select first_name,title,name
|
||||
from s_emp a
|
||||
join s_dept b
|
||||
on a.dept_id=b.id
|
||||
where a.dept_id=41;
|
||||
-- 查询部门为41的所有员工名字、部门名称、地区名称
|
||||
-- 数据源 s_emp s_dept s_region
|
||||
-- 关联关系 s_emp.dept_id s_dept.id s_dept.region_id s_region.id
|
||||
--
|
||||
select a.first_name 员工名字,b.name 部门名称, c.name 地区名称
|
||||
from s_emp a
|
||||
join s_dept b
|
||||
on a.dept_id=b.id
|
||||
join s_region c
|
||||
on b.region_id=c.id
|
||||
where a.dept_id=41;
|
||||
--自连接
|
||||
--查询部门41的员工的名字、职位和主管名字
|
||||
-- 数据源 s_emp a s_emp b
|
||||
-- a.manager_id=b.id
|
||||
|
||||
select a.first_name, a.title, b.first_name
|
||||
from s_emp a
|
||||
join s_emp b
|
||||
on a.manager_id=b.id
|
||||
where a.dept_id=41;
|
||||
```
|
||||
|
||||
#### 左外连接
|
||||
|
||||
- `LEFT OUTER JOIN` 左外连接
|
||||
|
||||
从左表返回所有的行,即使右表中没有匹配。如果右表中没有匹配,则结果为 NULL。OUTER可省略。
|
||||
|
||||

|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
--左外连接 left outer join on outer可以省略
|
||||
-- 以左表为准,左表中所有的数据都会被展示,如果在右表中没有匹配的数据,也展示,右表数据展示为null
|
||||
--查询员工的姓名、职位和客户姓名
|
||||
--数据源 s_emp s_customer
|
||||
--关系 s_emp.id s_customer.sales_rep_id
|
||||
|
||||
select a.first_name,a.title,b.name
|
||||
from s_emp a, s_customer b
|
||||
where a.id=b.sales_rep_id;
|
||||
|
||||
select a.first_name,a.title,b.name
|
||||
from s_emp a
|
||||
left outer join s_customer b
|
||||
on a.id=b.sales_rep_id;
|
||||
```
|
||||
|
||||
#### 右外连接
|
||||
|
||||
- `RIGHT OUTER JOIN` 右外连接
|
||||
|
||||
从右表返回所有的行,即使左表中没有匹配。如果左表中没有匹配,则结果为 NULL。OUTER可省略。
|
||||
|
||||

|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
-- 右外连接 以右表为准返回所有行 即使左表中查询不到相关数据 仍然显示但是有表数据显示为Null
|
||||
--right outer join on outer可以省略
|
||||
select a.first_name,a.title,b.name
|
||||
from s_emp a
|
||||
right outer join s_customer b
|
||||
on a.id=b.sales_rep_id;
|
||||
```
|
||||
|
||||
#### 全外连接
|
||||
|
||||
- `FULL OUTER JOIN` 全外连接
|
||||
|
||||
只要左表和右表其中一个表中存在匹配,则返回行。OUTER可省略。
|
||||
|
||||

|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
--全外连接
|
||||
-- full outer join on 其中 outer 可以省略
|
||||
-- 只要左表和右表中其中有一个存在匹配 返回该行
|
||||
select a.first_name,a.title,b.name
|
||||
from s_emp a
|
||||
full join s_customer b
|
||||
on a.id=b.sales_rep_id;
|
||||
```
|
||||
|
||||
### 子查询(嵌套查询)
|
||||
|
||||
- 子查询是一个完整的 SELECT 语句,可以拥有 GROUP BY、HAVING 子句,可以使用组函数,可以从多个表查询结果
|
||||
|
||||
- 子查询一般不包含 ORDER BY 子句,除非需要进行排名前几位的查询(Top-N)
|
||||
|
||||
- 如果子查询的外围语句是 SELECT 语句,则子查询内容必须用小括号界定,子查询里面不用分号结尾
|
||||
|
||||
- 子查询的作用:
|
||||
|
||||
1. 方便理解
|
||||
|
||||
2. 实现更复杂的查询
|
||||
|
||||
3. 提高查询效率
|
||||
|
||||
- 当直接查询某些数据很困难或办不到时,可以通过从“查询结果集”中再次提取数据集来实现复合查询。
|
||||
|
||||
- 子查询的位置通常出现在 WHERE 子句、HAVING 子句、FROM 子句
|
||||
|
||||
|
||||
#### WHERE 子句单行子查询
|
||||
|
||||
- 子查询返回结果是单行单列,使用单行比较符 `= != > >= < <=`
|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
-- where 子查询
|
||||
-- 单行子查询(单行单列)
|
||||
-- 查询最低工资的员工姓名、职位、工资
|
||||
--步骤1:找到最低工资
|
||||
select min(salary) from s_emp; -- 750
|
||||
--步骤2:找到对应的员工姓名、职位、工资
|
||||
select first_name,title,salary from s_emp where salary=750;
|
||||
-- 步骤3:做子查询替换
|
||||
select first_name,title,salary from s_emp where salary=(select min(salary) from s_emp);
|
||||
```
|
||||
|
||||
#### WHERE 子句多行子查询
|
||||
|
||||
- 子查询返回多行单列,使用多行比较符 `IN ANY ALL`
|
||||
|
||||
>IN 等于列表中的任意一个
|
||||
>ALL 和子查询返回的所有值比较(大于最大的,小于最小的)
|
||||
>ANY 和子查询返回的任意一个值比较(大于最小的,小于最大的)
|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
-- 多行子查询(多行单列) in all any
|
||||
-- 查询部门名称是Sales的部门所有员工姓名、职位
|
||||
--1.找到name是Sales的部门 的部门编号
|
||||
select id from s_dept where name='Sales';-- [31,32,33,34,35]
|
||||
--2.查找部门编号dept_id是 [31,32,33,34,35] 的姓名和职位
|
||||
select first_name,title from s_emp where dept_id in (31,32,33,34,35);
|
||||
--3.做子查询语句替换
|
||||
select first_name,title from s_emp where dept_id in (select id from s_dept where name='Sales');
|
||||
-- all 跟子查询中所有的值作比较 >all 大于最大值 <all小于最小值
|
||||
-- 查询部门编号比Sales部门都小的部门的所有员工的姓名和职位
|
||||
select id from s_dept where name='Sales';--[31,32,33,34,35]
|
||||
select first_name,title from s_emp where dept_id<all(select id from s_dept where name='Sales');
|
||||
-- any 跟子查询中所有的值作比较 >any 大于最小值 <any 小于最大值
|
||||
-- 查询部门编号比Sales部门中其中一个大的部门的所有员工姓名和职位
|
||||
select first_name,title from s_emp where dept_id>any(select id from s_dept where name='Sales');
|
||||
```
|
||||
|
||||
#### HAVING 子句子查询
|
||||
|
||||
- 子查询返回结果是单行单列或多行单列,也可以使用在 HAVING 子句
|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
--Having 子查询
|
||||
-- 查询部门平均工资比公司平均工资高的部门编号
|
||||
-- 1.查询公司的平均工资
|
||||
select avg(salary) from s_emp; --1255.08
|
||||
-- 2.查询部门的平均工资
|
||||
select dept_id, avg(salary)
|
||||
from s_emp
|
||||
group by dept_id
|
||||
having avg(salary)>1255.08;
|
||||
-- 3.替换
|
||||
select dept_id, avg(salary)
|
||||
from s_emp
|
||||
group by dept_id
|
||||
having avg(salary)>(select avg(salary) from s_emp);
|
||||
```
|
||||
|
||||
#### FROM 子句子查询
|
||||
|
||||
- 子查询返回结果是多行多列,可以使用在 FROM 子句作为数据源
|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
-- from 子查询(数据源)
|
||||
-- 子查询的结果是多行多列
|
||||
-- 查询工资从高到低排名前5的员工名字和职位
|
||||
select first_name,title
|
||||
from s_emp
|
||||
where rownum<6 order by salary desc; -- 执行顺序 from->where->select->order by
|
||||
-- 1.找到员工的姓名和职位 工资从高到低
|
||||
select first_name,title from s_emp order by salary desc; --子查询的结果 是一个两列(first_name,title)的临时表
|
||||
-- 2.截取前5个
|
||||
select * -- 可以用*获取数据源所有列即(first_name,title)
|
||||
from (select first_name,title from s_emp order by salary desc) -- 子查询的结果作为数据源
|
||||
where rownum<6;
|
||||
```
|
||||
|
||||
#### 子查询和多表查询结合
|
||||
|
||||
- 多行多列的子查询结果可以作为多表查询的数据源
|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
-- 多表查询和子查询相结合
|
||||
-- 多行多列的子查询结果可以作为多表查询的数据源
|
||||
-- 子查询产生的表如果列有分组函数 必须加别名
|
||||
-- 查询出每个部门名称、最高工资和人数
|
||||
--1.数据源 s_dept a s_emp b
|
||||
-- 部门的编号,最高工资 和人数
|
||||
select dept_id,max(salary),count(*) from s_emp group by dept_id;
|
||||
--2.关系 a.id b.dept_id
|
||||
select a.name 部门名称, c.maxsal 最高工资, c.count 人数
|
||||
from s_dept a
|
||||
left join (select dept_id deptid,max(salary) maxsal,count(*) count from s_emp group by dept_id) c
|
||||
on a.id=c.deptid;
|
||||
```
|
||||
|
||||
#### 子查询嵌套
|
||||
|
||||
- 子查询可以多层嵌套
|
||||
|
||||
**示例**
|
||||
|
||||
```plsql
|
||||
-- 子查询嵌套
|
||||
--查询工资比Henry所在部门平均工资高的所有员工的名字、职位、工资
|
||||
--1 求henry所在部门id
|
||||
select dept_id from s_emp where first_name='Henry';
|
||||
--2 部门的平均工资
|
||||
select avg(salary) from s_emp where dept_id=(select dept_id from s_emp where first_name='Henry');
|
||||
--3 以2为条件 过滤 取字段
|
||||
select first_name,title,salary
|
||||
from s_emp
|
||||
where salary>(select avg(salary) from s_emp where dept_id=(select dept_id from s_emp where first_name='Henry'));
|
||||
```
|
||||
|
||||
==**练习**==
|
||||
|
||||
```plsql
|
||||
-- 从订单表s_ord中查询出比销售代表编号sales_rep_id为11的所有订单金额total都低的订单信息
|
||||
SELECT * FROM s_ord WHERE total < (SELECT MIN(total) FROM s_ord WHERE sales_rep_id=11);
|
||||
```
|
||||
|
|
@ -0,0 +1,162 @@
|
|||
---
|
||||
title: 测试基础
|
||||
date: 2023-04-11 18:55:28.668
|
||||
updated: 2023-04-11 18:55:28.668
|
||||
url: /archives/ceshijichu
|
||||
categories:
|
||||
- 软件测试
|
||||
tags:
|
||||
- 测试基础
|
||||
---
|
||||
|
||||
# 测试基础
|
||||
|
||||
## 软件生命周期
|
||||
|
||||
### 计划
|
||||
|
||||
人员:项目经理
|
||||
|
||||
输出:项目计划
|
||||
|
||||
内容:项目目标,大致需求,团队人员,时间要求
|
||||
|
||||
### 需求分析
|
||||
|
||||
人员:产品经理、需求经理、需求工程师
|
||||
|
||||
输出:需求规格说明书(SRS)
|
||||
|
||||
内容:
|
||||
|
||||
1. 进一步确定用户需求
|
||||
2. 软件功能的具体描述
|
||||
3. 解决系统做什么的问题
|
||||
|
||||
### 设计
|
||||
|
||||
人员:系统架构师,资深开发工程师
|
||||
|
||||
输出:概要设计说明书(HLD)、详细设计说明书(LLD)
|
||||
|
||||
内容:
|
||||
|
||||
1. 软件-子系统-模块-函数
|
||||
2. 解决系统怎么做的问题
|
||||
|
||||
### 编码
|
||||
|
||||
人员:开发工程师
|
||||
|
||||
输出:项目代码或程序
|
||||
|
||||
内容:系统的具体实现
|
||||
|
||||
### 测试
|
||||
|
||||
人员:测试工程师
|
||||
|
||||
输出:测试计划,测试方案,测试用例,测试结果,缺陷报告,测试报告
|
||||
|
||||
内容:
|
||||
|
||||
1. 检查软件实现是否和需求一致
|
||||
2. 检查软件实现是否有遗漏
|
||||
|
||||
### 运维(维护)
|
||||
|
||||
人员:运维工程师
|
||||
|
||||
技术支持:系统的安装、部署、升级,问题排查
|
||||
|
||||
|
||||
|
||||
## 常见软件研发流程
|
||||
|
||||
### 瀑布模型
|
||||
|
||||
**串行的顺序流程**
|
||||
|
||||
- 从计划到维护
|
||||
- 重视文档,上一个阶段的输出是下一个阶段的输入
|
||||
- 一个阶段完成,资源会大部分释放给其它项目,一般是多项目共享资源
|
||||
- 一个阶段发现问题,返回上一个阶段解决
|
||||
- 适合需求在项目初始阶段可以明确的周期较长的项目
|
||||
- 软件要在项目的后期才能拿到
|
||||
|
||||
**分成三个阶段**
|
||||
|
||||
1. 定义阶段:计划和需求分析
|
||||
2. 开发阶段:设计,编码,测试
|
||||
3. 维护阶段:运行维护
|
||||
|
||||
### 螺旋模型
|
||||
|
||||
**串行的顺序流程**
|
||||
|
||||
- 分阶段实现功能,每个功能的开发都是采用瀑布模型
|
||||
- 较早可以看到能运行的软件
|
||||
- 一个原型完成后,经过风险评估进行下一个原型的开发
|
||||
|
||||
### RUP
|
||||
|
||||
**Rational Unified Process** 统一软件开发过程
|
||||
|
||||
并行流程
|
||||
|
||||
### IPD
|
||||
|
||||
**Integrated Product Development** 集成产品开发
|
||||
|
||||
并行流程
|
||||
|
||||
集成研发、生产、销售、采购,适合嵌入式研发企业和制造业
|
||||
|
||||
## 什么是软件测试
|
||||
|
||||
### 软件测试定义
|
||||
|
||||
软件测试是对软件的认知活动,软件测试不仅仅是发现缺陷,测试不一定要运行软件
|
||||
|
||||
### 测试的目的
|
||||
|
||||
- 证明:证明软件可用
|
||||
- 检测:检测软件质量,发现软件缺陷、错误和不足
|
||||
- 预防:预防缺陷的产生
|
||||
|
||||
tip:
|
||||
|
||||
尽早开始测试
|
||||
|
||||
尽早检查开发人员的工作是否有错误和遗漏的地方
|
||||
|
||||
分析已发现的缺陷,避免缺陷的重复出现
|
||||
|
||||
**项目不同阶段测试的目的**
|
||||
|
||||
- 项目早期:预防缺陷的产生
|
||||
- 项目计划评审
|
||||
- 需求文档评审
|
||||
- 设计文档评审
|
||||
- 测试用例评审
|
||||
- 项目中期:先发现严重缺陷,让软件尽快稳定
|
||||
- 项目后期:证明软件的功能都实现,可正常使用
|
||||
|
||||
## 什么是缺陷
|
||||
|
||||
缺陷、故障、失效的区别
|
||||
|
||||
- **缺陷是软件内隐藏的问题**
|
||||
- 缺陷诱发出来产生故障
|
||||
- 故障不能很好处理可能导致失效
|
||||
|
||||
### 缺陷分类
|
||||
|
||||
- 额外实现:做多了,实现了需求里没有的功能
|
||||
- 实现缺失:做少了,需求里的功能没有实现
|
||||
- 实现错误:做错了,需求里的功能实现了但不符合预期
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,127 @@
|
|||
---
|
||||
title: 测试方法
|
||||
date: 2023-04-12 14:57:27.964
|
||||
updated: 2023-04-13 07:58:41.373
|
||||
url: /archives/ceshifangfa
|
||||
categories:
|
||||
- 软件测试
|
||||
tags:
|
||||
- 测试基础
|
||||
---
|
||||
|
||||
## 黑白灰测试
|
||||
|
||||
### 黑盒测试
|
||||
|
||||
根据外在特性展开测试,只知道被测对象外在特性,不知道内部实现细节
|
||||
- 系统测试的主要依据是需求规格
|
||||
- 需求规格告诉我们软件的功能
|
||||
- 系统测试主要采用黑盒测试
|
||||
|
||||
### 白盒测试
|
||||
|
||||
根据内部结构开展测试,只知道被测对象内部实现细节,不知道外在特性
|
||||
|
||||
- 单元测试的主要依据是详细设计
|
||||
- 详细设计主要是函数的内部逻辑,也有函数的功能
|
||||
- 单元测试根据函数内部结构和功能开展测试,主要采用白盒测试
|
||||
|
||||
### 灰盒测试
|
||||
|
||||
同时根据外在特性和内部结构开展测试。既知道外在特性,也知道内部实现细节。
|
||||
|
||||
- 集成测试的主要依据是概要设计
|
||||
- 概要设计有每个模块的功能(外在特性),和每个模块内部有哪些函数(内部结构)
|
||||
- 集成测试根据模块功能以及内部组成来开展测试,采用灰盒测试
|
||||
|
||||
## 静态动态测试
|
||||
|
||||
### 静态测试
|
||||
|
||||
不执行被测对象进行测试
|
||||
|
||||
**分类**
|
||||
|
||||
- 人工静态测试 同行评审
|
||||
- 自动化静态测试 代码编译
|
||||
|
||||
**测试对象** 需求规格,概要设计,详细设计,代码,用户手册,帮助
|
||||
|
||||
### 动态测试
|
||||
|
||||
执行被测对象进行测试
|
||||
|
||||
**分类** 功能测试,性能测试,安全性测试,可靠性测试,语句覆盖测试
|
||||
|
||||
**测试对象** 代码,程序
|
||||
|
||||
## 人工自动化测试
|
||||
|
||||
### 人工测试
|
||||
|
||||
人工测试是自动化测试的基础
|
||||
|
||||
### 自动化测试
|
||||
|
||||
重复性高、技术难度低的工作可交给电脑完成
|
||||
|
||||
- 测试工作的特点
|
||||
|
||||
- 编写测试计划
|
||||
|
||||
只做一次,后面修改。不同人的测试计划差异很大。
|
||||
|
||||
- 编写测试方案
|
||||
|
||||
不同人的测试方案差异大。重复性不高,技术难度高。
|
||||
|
||||
- 编写测试用例
|
||||
|
||||
不同人的测试用例有差异。重复性不是很高,技术难度较高。
|
||||
|
||||
- 搭建测试环境
|
||||
|
||||
按照环境搭建手册搭建环境。不同人需要搭建相同的环境。重复性较高,技术难度中等。
|
||||
|
||||
**比较适合自动部署**
|
||||
|
||||
- 执行测试用例
|
||||
|
||||
按照步骤执行,会执行多次。重复性高,技术难度低。
|
||||
|
||||
**最适合自动化测试**
|
||||
|
||||
- 自动化测试优点
|
||||
|
||||
- 确保软件之前正常的功能没有问题
|
||||
- 提高回归测试效率
|
||||
- 具有很好的一致性
|
||||
|
||||
- 自动化测试局限性
|
||||
|
||||
- 当界面发生变化或者位置发生变化时,脚本失效
|
||||
- 脚本维护工作量大大增加
|
||||
- 无法提高测试效果
|
||||
- 很难发现新的问题
|
||||
|
||||
- 自动化测试何时引入
|
||||
|
||||
- **界面不发生变化时可引入**
|
||||
- **需要重复执行10次以上**
|
||||
|
||||
- 狭义自动化测试
|
||||
|
||||
- 用自动化测试脚本替代人做执行
|
||||
|
||||
- 广义自动化测试
|
||||
|
||||
- 四个活动是否可以利用计算机替代人的工作
|
||||
- 测试计划(自动分工)
|
||||
- 测试设计实现(测试用例自动生成)
|
||||
- 测试执行(测试环境自动搭建部署,测试用例自动执行)
|
||||
|
||||
- 自动化测试工具
|
||||
|
||||
- 基于图形用户界面(GUI)的自动化测试:Selenium,Appium,QTP
|
||||
- 基于应用程序接口(API)的自动化测试:Postman,SoapUI,JMeter
|
||||
|
||||
|
|
@ -0,0 +1,127 @@
|
|||
---
|
||||
title: 测试用例
|
||||
date: 2023-04-14 14:36:22.083
|
||||
updated: 2023-04-15 10:16:26.313
|
||||
url: /archives/ceshiyongli
|
||||
categories:
|
||||
- 软件测试
|
||||
tags:
|
||||
- 测试基础
|
||||
---
|
||||
|
||||
# 通用测试用例写作
|
||||
|
||||
## 什么是测试用例
|
||||
|
||||
**定义**
|
||||
|
||||
通过一组数据和操作步骤实现测试目的
|
||||
|
||||
**如何生成测试用例**
|
||||
|
||||
用户原始需求 > 产品需求 > 测试计划 > 测试方案 > 测试需求(测试要点)> 编写测 试用例
|
||||
|
||||
## 测试用例内容
|
||||
|
||||
### 用例编号
|
||||
|
||||
区分测试用例的一个标识
|
||||
|
||||
`项目名_测试阶段_测试项_子项序号`
|
||||
|
||||
测试阶段:单元测试 UT (Unit Test) 集成测试 IT (Integration Test) 系统测试 ST(System Test)
|
||||
|
||||
项目名和测试阶段可选
|
||||
|
||||
### 测试项目
|
||||
|
||||
单元测试 函数名
|
||||
|
||||
集成测试 模块名或接口名
|
||||
|
||||
系统测试 功能点,性能指标,界面元素
|
||||
|
||||
测试项目可以重复
|
||||
|
||||
### 测试标题
|
||||
|
||||
从哪个角度对测试目的进行测试,**描述测试的场景**,原则上标题不重复
|
||||
|
||||
如:验证正确的用户名和正确的密码登录
|
||||
|
||||
### 重要级别
|
||||
|
||||
影响测试用例执行顺序,和对应的测试点的重要性有关
|
||||
|
||||
常见的重要级别:高,中,低
|
||||
|
||||
**主要功能的正常操作优先级高**
|
||||
|
||||
主要功能的异常操作优先级中
|
||||
|
||||
次要功能的正常操作优先级中
|
||||
|
||||
次要功能的异常操作优先级低
|
||||
|
||||
### 预置条件
|
||||
|
||||
操作步骤一致,预置条件不一致,结果不一致
|
||||
|
||||
环境设置:在哪些环境执行测试,如兼容性测试用例的主环境和辅环境。已注册用户。
|
||||
|
||||
先运行其他测试用例
|
||||
|
||||
预置条件写和测试用例直接相关的条件
|
||||
|
||||
简化测试用例的步骤
|
||||
|
||||
- 使用管理员登录,进入用户管理模块
|
||||
- 已有用户admin,密码123456
|
||||
- 在以下环境执行:Win10+Edge, Win7+IE8,Win7+Firefox, Win8.1+Chrome
|
||||
|
||||
### 测试输入
|
||||
|
||||
输入的数据比较复杂或者是文件时使用
|
||||
|
||||
附件,测试用例有关的数据或文件上传
|
||||
|
||||
如果没有测试输入,把数据放入测试步骤中
|
||||
|
||||
- 用户名test,密码123465,确认密码123456,邮件地址test@163.com
|
||||
- 批量增加客户信息脚本
|
||||
|
||||
### 测试步骤
|
||||
|
||||
执行当前测试所需要经过的操作步骤,需要明确的给出每个步骤的描述
|
||||
|
||||
1. 打开网页 https://baidu.com
|
||||
|
||||
2. 测试输入 ruanjiansceshi
|
||||
3. 点击搜索按钮
|
||||
|
||||
### 预期结果
|
||||
|
||||
界面检查,数据库检查,测试用例通过失败标准
|
||||
|
||||
- 2秒内跳转到搜索结果页面
|
||||
- 检查搜索响应结果的准确性
|
||||
|
||||
### 其他可选内容
|
||||
|
||||
- 用例设计人员
|
||||
- 用例设计时间
|
||||
- 需要评审
|
||||
- 用例状态
|
||||
|
||||
示例:
|
||||
|
||||
| 用例编号 | 测试项目 | 测试标题 | 重要级别 | 预置条件 | 测试输入 | 操作步骤 | 与其结果 |
|
||||
| ---------- | -------- | ---------------------------------- | -------- | ------------ | ------------- | ---------------------------------------------- | ----------------------------------------------------------- |
|
||||
| search_001 | 搜索 | 验证搜索条件为拼音时的结果的准确性 | p1 | 已打开浏览器 | ruanjianceshi | 1、输入网址:https://baidu.com 2、输入测试数据 | 1、2秒内跳转至搜索结果页面2、搜索结果准确,符合需求规格要求 |
|
||||
|
||||
|
||||
|
||||
## 测试用例管理工具
|
||||
|
||||
禅道,JIRA,QC,TestLink
|
||||
|
||||
|
|
@ -0,0 +1,114 @@
|
|||
---
|
||||
title: 测试设计方法
|
||||
date: 2020-02-14 14:22:04.0
|
||||
updated: 2023-02-15 13:51:29.533
|
||||
url: /archives/测试设计方法
|
||||
categories:
|
||||
- 软件测试
|
||||
tags:
|
||||
- 测试基础
|
||||
---
|
||||
|
||||
# 测试设计方法
|
||||
## 等价类和边界值
|
||||
- 有效等价类
|
||||
- 正确的、有意的、合理的输入
|
||||
- 无效等价类
|
||||
- 错误的、无意义的、非法的输入
|
||||
|
||||
### 划分原则
|
||||
如果输入(输出)是一个取值范围,则划分成一个有效等价类和无效等价类
|
||||
```
|
||||
举例1:某招聘系统需要18~65周岁的员工(包含18~65)
|
||||
一个有效等价类:18~65(25,35,64)
|
||||
两个无效等价类:
|
||||
>65(79,100)
|
||||
<18(12,8)
|
||||
|
||||
举例2:身份证号码验证
|
||||
一个有效等价类:18位
|
||||
两个无效等价类:
|
||||
>18位
|
||||
<18位
|
||||
```
|
||||
|
||||
如果输入(输出)是一个集合或者必须如何的条件,则划分成一个有效等价类和一个无效等价类
|
||||
```
|
||||
举例1-集合:ZX04期学员在4号直播间上课
|
||||
一个有效等价类:ZX04期学员
|
||||
一个无效等价类:非ZX04期学员
|
||||
举例2-必须如何的条件:语句必须以“;”结尾
|
||||
一个有效等价类:以“;”结尾
|
||||
一个无效等价类:以其他符号结尾
|
||||
```
|
||||
|
||||
如果输入(输出)是一个布尔量,则划分成一个有效等价类和一个无效等价类
|
||||
```
|
||||
布尔量:逻辑正好相反的两个值(true,false)
|
||||
举例1-布尔量:卫生间(男卫生间;女卫生间)
|
||||
男卫生间:
|
||||
一个有效等价类:男士
|
||||
一个无效等价类:女士
|
||||
女卫生间:
|
||||
一个有效等价类:女士
|
||||
一个无效等价类:男士
|
||||
```
|
||||
|
||||
如果输入(输出)已经划分好有效无效等价类,针对有效等价类不同的值处理方式或者结果不一样,要细分成多个有效等价类和一个无效等价类
|
||||
```
|
||||
举例1-细分:某家公司发放年终奖,试用期满的员工可以享受年终奖,不满一年的员工享受
|
||||
0.5个月工资,满一年未到三年的享受2个月工资,满三年未到五年的享受4个月工资,满五年
|
||||
未到八年享受6月工资,满八年及以上享受10个月的工资
|
||||
无效等价类:试用期未满的员工
|
||||
有效等价类:试用期满的员工(细分)
|
||||
未满一年
|
||||
满一年未到三年
|
||||
满三年未到五年
|
||||
```
|
||||
|
||||
如果输入(输出)要同时满足多个条件,则划分成一个有效等价类和多个无效等价类。
|
||||
```
|
||||
举例1-多个条件:qq密码修改要在6~16位,首字符大写字母,包含大小写字母和数字
|
||||
一个有效等价类:所有条件都满足
|
||||
多个无效等价类:
|
||||
<6位;
|
||||
>16位;
|
||||
不包含小写字母;
|
||||
不包含数字;
|
||||
首字符非大写字母。
|
||||
|
||||
```
|
||||
|
||||
### 等价类划分法的使用步骤
|
||||
```
|
||||
步骤1:将需求规格说明书划分成需求子片段;
|
||||
步骤2:分析划分的需求子片段,找出输入条件;
|
||||
步骤3:分析每个输入条件,结合等价类划分原则划分等价类;
|
||||
步骤4:为划分好的等价类进行编号防止测试的遗漏;
|
||||
步骤5:从划分好的等价类中选取代表数据进行测试,直到所有的等价类全部被覆盖到(一条
|
||||
测试用例尽量覆盖多个有效等价类,一条测试用例只覆盖一个无效等价类)
|
||||
步骤6:结合测试用例编写规范(参照通用测试用例8大要素)生成测试用例
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,171 @@
|
|||
---
|
||||
title: 测试过程
|
||||
date: 2023-04-11 20:13:58.366
|
||||
updated: 2023-04-19 14:35:05.501
|
||||
url: /archives/ceshiguocheng
|
||||
categories:
|
||||
- 软件测试
|
||||
tags:
|
||||
- 测试基础
|
||||
---
|
||||
|
||||
# 测试过程
|
||||
|
||||
## 测试的四个阶段
|
||||
|
||||
### 单元测试阶段
|
||||
|
||||
检查实现出来的函数代码是否符合详细设计
|
||||
|
||||
- 测试依据:详细设计说明书
|
||||
- 测试对象:函数
|
||||
- 测试重点:函数内部逻辑实现是否正确
|
||||
- 评估标准:主要是逻辑覆盖率
|
||||
|
||||
### 集成测试阶段
|
||||
|
||||
检查实现出来的模块代码是否符合概要设计
|
||||
|
||||
- 测试依据:概要设计说明书
|
||||
- 测试对象:模块
|
||||
- 测试重点:模块功能是否正确实现,模块内部函数调用是否正确
|
||||
- 评估标准:主要是接口覆盖率
|
||||
|
||||
### 系统测试阶段
|
||||
|
||||
检查实现出来的软件代码是否符合需求规格
|
||||
|
||||
- 测试依据:需求规格说明书
|
||||
- 测试对象:整个软件
|
||||
- 测试重点:功能测试,界面测试,性能测试
|
||||
- 评估标准:主要是需求规格覆盖率
|
||||
|
||||
### 验收测试阶段
|
||||
|
||||
检查实现的软件代码是否符合**用户需求**
|
||||
|
||||
- 测试依据:用户需求
|
||||
- 测试对象:整个软件
|
||||
- 评估标准:用户需求是否满足
|
||||
|
||||
#### 正式验收测试
|
||||
|
||||
第三方评测
|
||||
|
||||
#### 用户验收测试
|
||||
|
||||
阿尔法测试
|
||||
|
||||
- 在开发环境下进行(不对外)
|
||||
- 开发主导
|
||||
- 处于受控状态,例如游戏内测
|
||||
|
||||
贝塔测试
|
||||
|
||||
- 在生产环境下进行
|
||||
- 处于不受控状态,例如游戏公测
|
||||
|
||||
## 回归测试
|
||||
|
||||
把已经测试的再测试一遍,四个阶段都会发生
|
||||
|
||||
原因:
|
||||
|
||||
1. 验证BUG是否修复
|
||||
2. 有没有引发新的问题
|
||||
|
||||
### 回归策略
|
||||
|
||||
- 选择性回归
|
||||
|
||||
- 覆盖修改法:发现bug的用例重新执行
|
||||
- 周边影响法:bug所在模块及有交互的模块全部覆盖
|
||||
- 指标达成法:bug修复涉及的代码全部覆盖,相关接口60%覆盖
|
||||
|
||||
- 完全回归
|
||||
|
||||
重新执行所有用例,工作量较大,一般配合自动化测试
|
||||
|
||||
## 测试的四个活动
|
||||
|
||||
每个测试阶段都可以细分为四个测试活动
|
||||
|
||||
### 测试计划活动
|
||||
|
||||
从管理角度规划和控制整个测试工作
|
||||
|
||||
人员:测试经理
|
||||
|
||||
输出:测试计划
|
||||
|
||||
内容:测试范围what,测试人员安排who,测试时间的安排when
|
||||
|
||||
### 测试设计活动
|
||||
|
||||
从技术角度规划和控制整个测试工作
|
||||
|
||||
人员:资深测试工程师
|
||||
|
||||
输出:测试方案
|
||||
|
||||
内容:测试怎样进行:测试方法和测试工具等
|
||||
|
||||
### 测试实现活动
|
||||
|
||||
**测试用例** 用一组数据按照一定的步骤检查软件的实现是否正确
|
||||
|
||||
人员:测试工程师
|
||||
|
||||
输出:测试用例
|
||||
|
||||
### 测试执行活动
|
||||
|
||||
根据测试用例对被测对象进行操作
|
||||
|
||||
人员:初级测试工程师
|
||||
|
||||
输出:搭建测试环境,执行用例,记录结果,提交缺陷报告,测试日报,测试分析报告,测试总结等
|
||||
|
||||
## 双V模型
|
||||
|
||||
**瀑布模型** 计划-需求分析-设计-编码-测试-维护
|
||||
|
||||
测试在编码之后进行,细分为:
|
||||
|
||||
单元测试:计划-设计-实现-执行
|
||||
|
||||
集成测试:计划-设计-实现-执行
|
||||
|
||||
系统测试:计划-设计-实现-执行
|
||||
|
||||
验收测试:计划-设计-实现-执行
|
||||
|
||||
|
||||
|
||||
**双V模型**
|
||||
|
||||
1. 需求分析完成输出SRS
|
||||
2. 架构师依据SRS进行HLD设计,同时测试依据SRS进行系统测试计划的设计和实现,输出系统测试计划、方案和用例
|
||||
3. 架构师完成HLD设计,开发进行LLD设计,同时测试依据HLD进行集成测试计划的设计和实现,输出集成测试计划、方案和用例
|
||||
4. 开发完成LLD设计,同时测试依据LLD进行单元测试计划的设计和实现,输出单元测试计划、方案、和用例
|
||||
5. 开发完成编码,测试进行代码审查
|
||||
6. 测试完成代码审查,进行单元测试执行
|
||||
7. 测试完成单元测试执行,进行集成测试执行
|
||||
8. 测试完成集成测试执行,进行系统测试执行
|
||||
|
||||
**代码审查**
|
||||
|
||||
代码编译,编码规则检查,注释率统计
|
||||
|
||||
**验证与确认**
|
||||
|
||||
验证:检测每一阶段形成的工作产品是否与前一阶段定义的规格一致
|
||||
|
||||
确认:检测每一阶段的工作产品是否与最初定义的需求规格一致
|
||||
|
||||
**特点**
|
||||
|
||||
1. 测试和开发同步展开工作
|
||||
2. 测试执行的顺序和开发的活动顺序相反
|
||||
3. 测试计划、设计、实现和执行分离
|
||||
4. 系统测试计划、设计、实现最早开始,系统测试执行最晚结束
|
||||
|
|
@ -0,0 +1,59 @@
|
|||
---
|
||||
title: 简单理解C/S和B/S架构
|
||||
date: 2023-04-19 17:20:32.903
|
||||
updated: 2023-04-19 19:10:12.3
|
||||
url: /archives/bs-cs
|
||||
categories:
|
||||
- 软件测试
|
||||
tags:
|
||||
- 测试基础
|
||||
---
|
||||
|
||||
## C/S架构
|
||||
|
||||
全称Client/Server,即客户端/服务器
|
||||
|
||||
例如:QQ、微信、VScode等等
|
||||
|
||||
优点:
|
||||
|
||||
1. 客户端与服务端直接连接,响应速度快
|
||||
2. 界面多样性,满足客户个性化要求
|
||||
3. 能实现非常复杂的业务流程
|
||||
4. 可以面对有限的群体,机密性较好
|
||||
|
||||
缺点:
|
||||
|
||||
1. 客户端需要安装程序,不能实现快速部署和配置
|
||||
2. 兼容性差,不同系统需要开发不同版本的程序
|
||||
3. 升级成本较高(需要维护多版本)
|
||||
|
||||
## B/S架构
|
||||
|
||||
全称Browser/Server,即浏览器/服务器
|
||||
|
||||
客户端使用浏览器,服务端实现业务逻辑,可以认为是一种特殊的C/S架构
|
||||
|
||||
例如:淘宝、京东、博客论坛等等
|
||||
|
||||
优点:
|
||||
|
||||
1. 具有分布性特点,可以随时随地进行查询、浏览等业务处理
|
||||
2. 业务扩展相对简单,通过服务端即可增加新功能
|
||||
3. 维护简单方便,服务端更新即可实现所有用户同步更新
|
||||
|
||||
缺点:
|
||||
|
||||
1. 个性化特点明显降低,无法实现个性化的功能和要求,例如(QQ)
|
||||
2. 操作是以鼠标为最基本的操作方式,无法满足快速操作要求
|
||||
3. 页面动态刷新,响应速度明显降低
|
||||
|
||||
## P2P 架构
|
||||
|
||||
全称Point to Point,即点对点
|
||||
|
||||
例如:迅雷、飞秋
|
||||
|
||||
优点:速度快
|
||||
|
||||
缺点:占用系统资源多
|
||||
|
|
@ -0,0 +1,24 @@
|
|||
---
|
||||
title: 简谱的构造和唱名
|
||||
date: 2022-06-16 13:17:00.04
|
||||
updated: 2022-09-30 21:47:40.843
|
||||
url: /archives/简谱的构造和唱名
|
||||
categories:
|
||||
tags:
|
||||
---
|
||||
|
||||
# 简谱结构
|
||||
唐(李白) 词曲作者
|
||||
1=C 调号 (音唱在哪些音高上)
|
||||
4/4 柔情的 音乐的速度和情绪
|
||||
|
||||
# 唱名
|
||||
```txt
|
||||
1 2 3 4 5 6 7
|
||||
do re mi fa sol la si
|
||||
```
|
||||
|
||||
# 钢琴键的结构
|
||||
```txt
|
||||
C C#/D♭ D D#/E♭ E F F#/G♭ G G#/A♭ A A#/B♭ B
|
||||
```
|
||||
|
|
@ -0,0 +1,278 @@
|
|||
---
|
||||
title: 系统测试
|
||||
date: 2023-04-14 10:55:45.782
|
||||
updated: 2023-04-14 14:43:06.933
|
||||
url: /archives/xtceshi
|
||||
categories:
|
||||
- 软件测试
|
||||
tags:
|
||||
- 测试基础
|
||||
---
|
||||
|
||||
## 什么是系统测试
|
||||
|
||||
检查已经集成的软件是否和需求规格说明书一致
|
||||
|
||||
**系统种类**:桌面软件,Web 网站,客户端软件,移动 App,小程序,智能设备
|
||||
|
||||
单元测试 集成测试 系统测试比较
|
||||
|
||||
- 单元测试
|
||||
- 对象:函数
|
||||
- 依据:详细设计 LLD
|
||||
- 重点:函数的功能和内部的逻辑
|
||||
- 评估:逻辑覆盖率
|
||||
- 方法:白盒测试为主
|
||||
- 集成测试
|
||||
- 对象:模块
|
||||
- 依据:概要设计 HLD
|
||||
- 重点:模块的功能和函数间的调用(接口)
|
||||
- 评估:接口覆盖率
|
||||
- 方法:灰盒测试
|
||||
- 系统测试
|
||||
- 对象:整个软件
|
||||
- 依据:需求规格说明书 SRS
|
||||
- 重点:功能测试,性能测试,安全性测试,界面测试 ...
|
||||
- 评估:需求规格覆盖率
|
||||
- 方法:黑盒测试为主
|
||||
|
||||
## 系统测试活动
|
||||
|
||||
**计划**
|
||||
|
||||
输入:需求规格
|
||||
|
||||
输出:系统测试计划
|
||||
|
||||
**设计**
|
||||
|
||||
输入:需求规格,系统测试计划
|
||||
|
||||
输出:系统测试方案
|
||||
|
||||
**实现**
|
||||
|
||||
输入:需求规格,系统测试计划,系统测试方案
|
||||
|
||||
输出:系统测试用例,系统**预测试**用例
|
||||
|
||||
**执行**
|
||||
|
||||
输入: 系统测试计划,系统测试方案,系统测试用例,系统预测试用例,集成测试报告
|
||||
|
||||
输出:系统测试结果,系统测试缺陷报告,系统测试报告
|
||||
|
||||
## 系统测试类型
|
||||
|
||||
#### 功能测试
|
||||
|
||||
质量模型中的 **功能性**
|
||||
|
||||
分类:单功能测试,功能交互测试,业务场景测试
|
||||
|
||||
#### 性能测试
|
||||
|
||||
质量模型中 **效率**
|
||||
|
||||
性能测试指标:响应时间,吞吐量、吞吐率(单位时间内的吞吐量),TPS(每秒处理事务数) ,并发用户数,内存占用,CPU占用,磁盘占用,功耗,流量
|
||||
|
||||
性能测试是一个大的测试类型,是所有性能相关测试的统称。可以细分为几个子测试类型:
|
||||
|
||||
- **负载测试(相对并发)**
|
||||
|
||||
测试系统在各种负载情况下,是否满足 **需求规格说明书各项性能指标** 相关要求,并测试出**系统最大负载**
|
||||
|
||||
主要测试系统的**能力**
|
||||
|
||||
- **压力测试**
|
||||
|
||||
测试系统在 **极限负载** 况下是否会崩溃,各项性能指标在 **长时间运行** 的情况下是否稳定
|
||||
|
||||
主要测试系统的**耐力**
|
||||
|
||||
- **容量测试**
|
||||
|
||||
测试系统可处理 **同时在线的最大用户数**
|
||||
|
||||
只关注数量多少,不关注速度多快
|
||||
|
||||
- **基准测试**
|
||||
|
||||
用于一些大型的网站的性能测试
|
||||
|
||||
找一台普通服务器,针对 **不同版本的软件** 进行小容量的测试,进行对比
|
||||
|
||||
- **并发测试**(绝对并发)
|
||||
|
||||
测试多个用户同时访问同一个应用、同一个模块或者数据记录时是否存在问题
|
||||
|
||||

|
||||
#### 界面测试
|
||||
|
||||
质量模型中 **易用性的易理解性和吸引性**
|
||||
|
||||
又叫 GUI 测试。有些公司把界面测试并入功能测试
|
||||
|
||||
- 测试界面元素的显示
|
||||
- 界面元素大小,形状,色彩
|
||||
- 界面元素文字的字体,字号,对齐
|
||||
- 光标位置
|
||||
- 输入回显
|
||||
- 测试界面元素的行为
|
||||
- 输入限制,输入检查,输入提醒
|
||||
- 默认值
|
||||
- 出错信息位置
|
||||
- 测试界面的布局
|
||||
- 各界面元素所在位置
|
||||
- 各界面元素对齐方式
|
||||
- 各界面元素之间的间距
|
||||
- 各界面元素之间的色彩搭配
|
||||
|
||||
#### 易用性测试
|
||||
|
||||
质量模型中 **易用性的易操作性**
|
||||
|
||||
软件操作方便,操作步骤少
|
||||
|
||||
- 桌面软件菜单级数不超过 3 级
|
||||
- 电商网站分类导航不超过 3 级
|
||||
- 输入区域切换使用快捷键
|
||||
- 右键菜单
|
||||
- 手机App单手操作
|
||||
|
||||
#### 兼容性测试
|
||||
|
||||
质量模型中 **可移植性的适应性**
|
||||
|
||||
考虑不同环境下功能测试,界面测试。
|
||||
|
||||
- 客户端软件:兼容不同操作系统
|
||||
- web软件:兼容不同浏览器
|
||||
- 移动App:兼容不同手机、型号、分辨率、操作系统、操作系统版本
|
||||
|
||||
#### 安全性测试
|
||||
|
||||
质量模型中 **功能性的保密安全性**
|
||||
|
||||
- **数据的安全性**:考虑敏感数据从产生-传输-存储全程加密
|
||||
|
||||
- **权限的安全性**:水平越权、垂直越权、第三方授权
|
||||
|
||||
- **安全漏洞**
|
||||
|
||||
#### 安装测试
|
||||
|
||||
质量模型中 **可移植性的易安装性易替换**
|
||||
|
||||
- 安装/升级前测试
|
||||
- 检查安装包中文件是否齐全(包含环境软件)
|
||||
- 检查安装包中是否有病毒或木马
|
||||
- 安装/升级中测试
|
||||
- 安装流程测试 初次安装,默认配置安装,自定义配置安装
|
||||
- 升级降级测试
|
||||
- 异常情况测试 安装目录没有权限,空间不够,安装过程中中止
|
||||
- 安装/升级后测试
|
||||
- 程序文件的目录及子目录是否正确产生
|
||||
- 是否存在无用的目录、子目录、程序文件和临时文件
|
||||
- 安装日志检查
|
||||
- 测试安装是否完整
|
||||
- 测试安装好的软件是否可运行
|
||||
- 软件的卸载测试
|
||||
|
||||
#### 可靠性测试
|
||||
|
||||
质量模型中 **可靠性**
|
||||
|
||||
- 稳定性测试
|
||||
|
||||
常规负载连续运行较长时间不出现问题,如网站运行一周7*24
|
||||
|
||||
- 容错性测试
|
||||
|
||||
- 恢复性测试
|
||||
|
||||
从灾难或出错中能否很好地恢复
|
||||
|
||||
- 异常测试
|
||||
|
||||
软件系统故障,断电,硬件及有关设备故障,通信故障和错误
|
||||
|
||||
#### 文档测试
|
||||
|
||||
对用户使用手册,系统部署文档,帮助(包括App安装后首次运行的向导)等文档进行测试。 检验文档的完整性,正确性,一致性,易理解性和易浏览性
|
||||
|
||||
#### 网络测试
|
||||
|
||||
不同网络环境下软件是否正常运行
|
||||
|
||||
- WIFI
|
||||
- 2G,3G,4G,5G 移动网络
|
||||
- 弱网
|
||||
- 无网
|
||||
|
||||
## 系统测试环境
|
||||
|
||||
#### 环境组成
|
||||
|
||||
- **硬件**
|
||||
|
||||
PC,服务器,网络设备,打印机......
|
||||
|
||||
- **软件**
|
||||
|
||||
操作系统,Web服务器软件,应用服务器软件,数据库软件,软件支持平台(JDK) 被测软件,测试数据,测试脚本,浏览器
|
||||
|
||||
#### 环境分类
|
||||
|
||||
- 主测试环境(例如win10+chrome+1920*1080)
|
||||
- 辅测试环境(例如win7+ie8+1024*768)
|
||||
- 真实环境(如弱网考虑电梯、地下停车场)
|
||||
- 仿真环境(如VMware,QNET,模拟器)
|
||||
|
||||
#### 测试数据准备
|
||||
|
||||
产品数据(注意隐私和安全,脱敏处理),工具生成,捕获数据,手工构造,随机数据
|
||||
|
||||
## 系统测试执行
|
||||
|
||||
#### 测试环境搭建
|
||||
|
||||
#### 系统测试预测试
|
||||
|
||||
基本功能检查,检查软件质量是否满足后续测试要求,也叫**冒烟测试**
|
||||
|
||||
**每日构建** Daily Build 每天自动完整编译最新代码
|
||||
|
||||
#### 转系统测试评审(可选)
|
||||
|
||||
开会确定是否能开始正式的系统测试执行
|
||||
|
||||
- 评审点
|
||||
1.冒烟测试是否通过
|
||||
2.测试用例是否完成并经过评审
|
||||
3.测试人员是否到位
|
||||
4.测试工具是否到位且进行了相关培训
|
||||
|
||||
#### 执行测试用例
|
||||
|
||||
- 填写测试记录
|
||||
1.测试用例执行人员
|
||||
2.测试用例执行时间
|
||||
3. 测试用例执行结果
|
||||
4.问题单号
|
||||
5.执行测试用例数统计
|
||||
6.测试记录提交人员
|
||||
|
||||
- 编写测试日报
|
||||
|
||||
汇报每天执行情况
|
||||
|
||||
测试日报内容:执行情况,发现缺陷情况,**存在的问题以及需要的帮助**
|
||||
|
||||
- 缺陷管理
|
||||
|
||||
提交缺陷报告,跟踪缺陷状态,回归测试验证缺陷
|
||||
|
||||
#### 编写测试报告(软件)和测试总结(个人)
|
||||
|
||||
测试执行结束时
|
||||
|
|
@ -0,0 +1,132 @@
|
|||
---
|
||||
title: 系统测试分析方法
|
||||
date: 2023-04-15 10:15:57.728
|
||||
updated: 2023-04-21 15:19:23.102
|
||||
url: /archives/xtcs-fenxifangfa
|
||||
categories:
|
||||
- 软件测试
|
||||
tags:
|
||||
- 测试基础
|
||||
---
|
||||
|
||||
## 测试需求分析
|
||||
|
||||
### 需求分析 的原因
|
||||
|
||||
需求差产生的风险
|
||||
|
||||
- 客户参与不足导致产品无法被接受
|
||||
- 需求变更频繁
|
||||
- 摸棱两可的需求
|
||||
- 不必要的特性
|
||||
|
||||
### 测试需求分析的目的
|
||||
|
||||
- 解决测试的完整性和充分性
|
||||
- 把该测试的地方都测试到
|
||||
|
||||
### 测试需求来源获取
|
||||
|
||||
- 用户/业务需求
|
||||
|
||||
项目标书,问卷调查,原型分析,市场报告
|
||||
|
||||
- 开发需求
|
||||
|
||||
设计需求,设计规格
|
||||
|
||||
- 协议/标准/规范
|
||||
|
||||
- 继承性需求
|
||||
|
||||
- 测试案例库
|
||||
|
||||
- 竞争分析
|
||||
|
||||
### 测试需求项整理
|
||||
|
||||
- 原因
|
||||
- 不同来源范围提取出来的原始测试需求可能存在重复和冗余,需要进行整理
|
||||
- 整理后的原始测试需求,作为后续原始测试需求分析活动的输入
|
||||
- 开发需求提取
|
||||
- 一条开发需求作为一条测试需求
|
||||
- 一条需求拆分成多条测试原始需求
|
||||
- 多条开发需求合并为一条测试原始需求
|
||||
- 协议/标准/规范提取
|
||||
- 标准一致性测试
|
||||
- 开发文档质量无法满足要求
|
||||
- 协议支撑类功能测试
|
||||
- 用户需求提取
|
||||
- 每个用户需求至少有一条对应的测试需求
|
||||
|
||||
### 测试需求分析方法
|
||||
|
||||
#### 质量模型分析法
|
||||
|
||||
质量模型分析从多个角度对单个功能进行测试
|
||||
|
||||
从各个测试类型去分析:功能测试、性能测试、安全测试、可靠性测试、界面测试、易用性测试、兼容 性测试、文档测试
|
||||
|
||||
#### 功能交互分析法
|
||||
|
||||
**原因**
|
||||
|
||||
- 产品功能不是独立的,功能之间存在交互关系
|
||||
- 功能交互分析对功能之间的相互影响进行测试
|
||||
- 防止有交互功能的遗漏,提高功能测试的覆盖率和完整性、充分性
|
||||
|
||||
**功能交互的场景**
|
||||
|
||||
- 使用同一个资源:文件,数据
|
||||
- 功能同时使用:音乐、视频、电话
|
||||
- 功能顺序使用:注册-登录
|
||||
|
||||
**功能交互的层次**
|
||||
|
||||
- 模块内功能的交互(聊天时转账、发红包)
|
||||
- 模块间功能的交互(下单和支付,手机里联系人与微信、钉钉等交互)
|
||||
- 子系统间的交互:买家和卖家子系统交互
|
||||
- 平台间的交互:Web和App端交互
|
||||
|
||||
#### 用户场景分析法
|
||||
|
||||
- **用户** 从用户角度出发,关注每个用户是如何使用和影响被测功能特性,比如同一款手机,年轻人 和老年人的关注点不一样
|
||||
- **场景** 将多个功能串起来使用,场景往往对应**业务流程**
|
||||
|
||||
## 测试分析思路
|
||||
|
||||
### 测试计划阶段
|
||||
|
||||
确定系统测试需求
|
||||
|
||||
- 获取测试需求
|
||||
- 整理测试需求
|
||||
- 分析测试需求 质量模型分析法,功能交互分析法,用户场景分析法
|
||||
- 确定系统测试类型
|
||||
- 功能测试
|
||||
- 性能测试
|
||||
- GUI 测试
|
||||
- 安全性测试
|
||||
- 安装测试
|
||||
- 可靠性测试
|
||||
- 兼容性测试
|
||||
- 文档测试
|
||||
|
||||
### 测试设计阶段
|
||||
|
||||
系统测试子项细分
|
||||
|
||||
- 功能测试
|
||||
- 从控件的功能出发
|
||||
- 从数据的生命周期出发
|
||||
- 根据用户的使用
|
||||
- GUI测试
|
||||
- 控件的显示
|
||||
- 整体的布局
|
||||
- 性能测试
|
||||
- 验证性能需求
|
||||
- 性能工具确定
|
||||
|
||||
### 测试实现阶段
|
||||
|
||||
利用各种测试用例设计方法覆盖测试子项的需求
|
||||
|
|
@ -0,0 +1,421 @@
|
|||
---
|
||||
title: 系统测试设计方法
|
||||
date: 2023-04-25 20:00:29.222
|
||||
updated: 2023-04-25 20:00:29.222
|
||||
url: /archives/xi-tong-ce-shi-she-ji-fang-fa
|
||||
categories:
|
||||
- 软件测试
|
||||
tags:
|
||||
- Base
|
||||
---
|
||||
|
||||
## 1.等价类划分
|
||||
|
||||
### 1.1等价类概念
|
||||
|
||||
- 等价类
|
||||
|
||||
某个输入域的子集合,在这个集合中每一个输入条件都是等效的, 如果其中一个输入不能导致问题 发生,那么集合中其它输入条件进行测试也不可能发现错误
|
||||
|
||||
- 有效等价类
|
||||
|
||||
合理的输入数据 指满足产品规格说明的输入数据,即有效的、有意义的输入数据所构成的集合。 利用有效等价类, 可以检验程序是否满足规格说明所规定的功能和性能。
|
||||
|
||||
- 无效等价类
|
||||
|
||||
不合理的输入数据
|
||||
|
||||
不满足程序输入要求或者无效的输入数据所构成的集合。 利用无效等价类,可以测试程序的容错性 (对异常输入情况的处理)。
|
||||
|
||||
### 1.2等价类划分方式
|
||||
|
||||
**如果输入条件规定了输入值的集合,或者 “必须如何”。 则可以确立一个有效等价类和一个无效等价类。**
|
||||
|
||||
注册的时候选择性别,男或女,默认没有选择,性别是必填项
|
||||
|
||||
- 有效等价类:男或女
|
||||
- 无效等价类:不选择
|
||||
|
||||
**如果输入条件规定了取值范围,或值的个数, 则可以确立一个有效等价类和两个无效等价类。**
|
||||
|
||||
取款金额100到5000
|
||||
|
||||
- 有效等价类:100到5000
|
||||
- 无效等价类:小于100,大于5000
|
||||
|
||||
**如果输入条件是一个布尔量, 则可以确定一个有效等价类和一个无效等价类。**
|
||||
|
||||
安装软件时必须同意协议才能继续安装
|
||||
|
||||
- 有效等价类:同意
|
||||
- 无效等价类:不同意
|
||||
|
||||
**如果规定了的一组输入数据(N个输入值), 且要对每个输入值分别进行处理。 这时可确立N个有效等 价类和一个无效等价类**
|
||||
|
||||
考试,>=60分及格,60-70是合格,71-85是良好,86-100优秀
|
||||
|
||||
- 有效等价类:60-70,71-85,86-100
|
||||
- 无效等价类:小于60
|
||||
|
||||
**如果规定了输入数据必须遵守的一系列规则, 则可以确立一个有效等价类(符合规则) 和多个无效等价 类(从不同角度违反规则)**
|
||||
|
||||
注册的用户名要求必须由英文字母和数字组成,长度3-20之间,不能以数字开头
|
||||
|
||||
- 有效等价类:由英文字母和数字组成,长度3-20之间,以英文字母开头
|
||||
- 无效等价类:包含文字,包含特殊字符(含空格),长度小于3,长度大于20,以数字开头
|
||||
|
||||
### 1.3等价类划分步骤
|
||||
|
||||
1. 确定输入框
|
||||
|
||||
2. 确定输入条件
|
||||
|
||||
3. 划分有效等价类和无效等价类
|
||||
|
||||
4. 用测试用例覆盖有效等价类
|
||||
|
||||
5. 用测试用例覆盖无效等价类
|
||||
|
||||
### 1.4等价类划分实例
|
||||
|
||||
```
|
||||
6~18个字符,可使用字母、数字、下划线,需要以字母开头
|
||||
```
|
||||
|
||||
| 规则 | 有效等价类 | 无效等价类 |
|
||||
| ---- | --------------------- | ----------------------------------------------------- |
|
||||
| 长度 | 1、6-18个字符 | 2、小于6个字符 3、大于18个字符 |
|
||||
| 组长 | 4、字母、数字、下划线 | 5、包含文字 6、包含特殊字符(包含空格,不包含下划线) |
|
||||
| 开头 | 7、字母 | 8、数字 9、下划线 |
|
||||
|
||||
| 用例编号 | 覆盖等价类 | 测试输入数据 |
|
||||
| -------- | ---------- | ------------ |
|
||||
| 1 | 1,4,7 | |
|
||||
| 2 | 2,4,7 | |
|
||||
| 3 | 3,4,7 | |
|
||||
| 4 | 1,5,7 | |
|
||||
| 5 | 1,6,7 | |
|
||||
| 6 | 1,4,8 | |
|
||||
| 7 | 1,4,9 | |
|
||||
|
||||
|
||||
|
||||
### 1.5等价类划分特点
|
||||
|
||||
只考虑单个输入的覆盖,不考虑输入的组合
|
||||
|
||||
### 1.6使用场景
|
||||
|
||||
单个输入或输出
|
||||
|
||||
## 2.边界值分析
|
||||
|
||||
### 2.1边界值概念
|
||||
|
||||
- 指不同等价类之间的边界,**边界值分析法是对等价类划分法的一种补充**,根据经验边界是问题的多发区
|
||||
- 错误隐藏在角落里,问题聚集在边界上,如果边界附近的取值不会导致程序出错,那么其它取值导致程序错误的可能也很小
|
||||
|
||||
### 2.2边界值的分类
|
||||
|
||||
- **上点 边界上的点**
|
||||
|
||||
如果域的边界是封闭的,上点就在域范围内
|
||||
|
||||
如果域的边界是开放的,上点就在域范围外
|
||||
|
||||
范围的边界值一定是上点
|
||||
|
||||
- **离点** 离边界最近的点
|
||||
|
||||
如果域的边界是封闭的,离点就在域范围外
|
||||
|
||||
如果域的边界是开放的,离点就在域范围内
|
||||
|
||||
如果某个上点是有效的,离点就是无效的。如果某个上点是无效的,离点就是有效的
|
||||
|
||||
- **内点** 区间内除上点和离点之外的任意一个点
|
||||
|
||||
> 上点一定是边界上的点,不管封闭区间还是开放区间。 上点和离点在不同的等价类,如果上点是有效等价类,则离点是无效等价类;如果上点是无 效等价类,则离点是有效等价类。
|
||||
|
||||
### 2.3边界值分析步骤
|
||||
|
||||
1. 分析输入参数的类型
|
||||
2. 等价类划分(可选)
|
||||
3. 确定边界 确定上点、离点、内点
|
||||
4. 确定测试用例
|
||||
5. 选择这些上点、离点、内点或者这些点的组合形成测试项
|
||||
|
||||
### 2.4边界值分析实例
|
||||
|
||||
**实例演示**
|
||||
|
||||
驾照年龄范围18到70
|
||||
|
||||
上点:18,70
|
||||
|
||||
离点:17,71
|
||||
|
||||
内点:20
|
||||
|
||||
输入值范围 -3 到 4 ,不含边界,整数
|
||||
|
||||
上点:-3,4
|
||||
|
||||
离点:-2,3
|
||||
|
||||
特殊边界:0
|
||||
|
||||
下拉框选择国家,默认请选择,范围从阿富汗到津巴布韦
|
||||
|
||||
上点:阿富汗,津巴布韦
|
||||
|
||||
离点:请选择
|
||||
|
||||
> (6,18)为开区间,不包含6和18
|
||||
>
|
||||
> 有效值:7~17的数字
|
||||
>
|
||||
> 无效值:小于等于6,大于等于18的数字
|
||||
>
|
||||
> 上点:6,18 为无效等价类
|
||||
>
|
||||
> 离点:7,17 为有效等价类
|
||||
|
||||
>
|
||||
>
|
||||
>[6,18]为闭区间,包含6和18
|
||||
>
|
||||
>有效值:6~18的数字
|
||||
>
|
||||
>无效值:小于6,大于18
|
||||
>
|
||||
>上点:6,18 为有效等价类
|
||||
>
|
||||
>离点:5,19 为无效等价类
|
||||
|
||||
### 2.5边界值分析使用场景
|
||||
|
||||
单个输入规定了一个输入范围
|
||||
|
||||
单个输入是一个有序的集合(下拉框)
|
||||
|
||||
## 3.输入域测试
|
||||
|
||||
在等价类划分法和边界值分析法的基础上考虑特殊值测试等其它情况
|
||||
|
||||
### 3.1输入域步骤
|
||||
|
||||
1. 等价类划分法
|
||||
2. 边界值分析
|
||||
3. 特殊值测试
|
||||
4. 极限值测试
|
||||
|
||||
### 3.2特殊值测试
|
||||
|
||||
日期特殊值
|
||||
|
||||
- 2月份的日范围,也数值闰年2月有29天(闰年:能被4整除且不能被100整除;或能被400整除)
|
||||
- 年的表示使用两位数,特殊值是千年虫
|
||||
- 时间使用时间戳方式保存时,特殊值2038年,最大能表示的日期是2038年1月19日(32位操作系 统的int数据类型最大值是2147483647)
|
||||
|
||||
手机号码特殊值
|
||||
|
||||
- 110、120、119等紧急号码
|
||||
- 10086,10000,95555等客服号码
|
||||
- 虚拟网短号 601
|
||||
- 13800138000 中国移动充值卡充值中心的号码
|
||||
|
||||
### 3.3极限值测试
|
||||
|
||||
某个密码输入框允许最大输入100个字符,密码的最大长度是12
|
||||
|
||||
上点是长度12,离点是长度13,极限值考虑长度100
|
||||
|
||||
界面长度如果没有限制,可以看数据存储长度进行验证(定义数据类型的可输入最大长度)
|
||||
|
||||
### 3.4输入域场景测试
|
||||
|
||||
各种单个输入框
|
||||
|
||||
## 4.输出域测试
|
||||
|
||||
系统的输入和输出一般不是线性关系,输入域的等价类划分和边界值分析不一定覆盖输出域的等价类和 边界值,需要从输出的测试点考虑输入值。
|
||||
|
||||
### 4.1输出域步骤
|
||||
|
||||
1. 从输出角度考虑等价类划分,一般输出没有无效等价类
|
||||
2. 分析输出等价类的边界值
|
||||
3. 根据需要覆盖的输出值反推输入值
|
||||
4. 转化成测试用例
|
||||
|
||||
### 4.2输出域实例
|
||||
|
||||
- 外币兑换
|
||||
|
||||
输入人民币数值,100到40000。输出美元数值,可以兑换的美元范围100到5000。
|
||||
|
||||
输出的有效等价类是100到5000,上点是100和5000。覆盖输出的边界,倒推输入是700和35000
|
||||
|
||||
- 个人信息完整显示
|
||||
|
||||
注册时填写所有信息项,为了验证每个信息项都能正常展示。
|
||||
|
||||
- 查询结果导出时excel每个sheet最大行数为65535
|
||||
|
||||
|
||||
|
||||
### 4.3输出域使用场景
|
||||
|
||||
格式转换,查询结果导出
|
||||
|
||||
- 一般只有当输出比较复杂的时候可能会使用到,实际工作中应用较少。
|
||||
|
||||
## 5.正交实验法
|
||||
|
||||
### 5.1正交实验法概念
|
||||
|
||||
- 正交试验设计法,是从大量的试验点中挑选出适量的有代表性的点, 应用依据迦罗瓦理论导出的正 交表,合理地安排试验的一种科学试验设计方法。
|
||||
- 利用正交表从全排列组合中自动筛选出若干组合进行测试。**任意两个因子的不同状态都同时组合在 一条规则里。**
|
||||
- **原理** 用尽量少的测试用例覆盖输入的两两组合,**如果两两组合没问题,更复杂组合问题不大。**
|
||||
|
||||
### 5.2正交表组成
|
||||
|
||||

|
||||
|
||||
- 因素(因子)Column 输入条件
|
||||
|
||||
所有影响实验指标的条件,要测试的功能点,即有哪些输入
|
||||
|
||||
- 水平(因子的状态) 输入条件的取值
|
||||
|
||||
影响试验因子的状态,即单个因素能够取得的值的最大个数。即输入的取值个数。
|
||||
|
||||
- 实验 Experiment Number
|
||||
|
||||
因素和水平的组合,对应测试用例
|
||||
|
||||
### 5.3正交实验法步骤
|
||||
|
||||
1. 确定要组合的输入
|
||||
2. 有哪些因子(变量)
|
||||
3. 每个因子有哪几个状态(变量的取值)
|
||||
4. 如果因子或状态过多,可以删除一部分重要性较小的因子或状态,使生成的测试用例集缩减到允许范围
|
||||
5. 选择合适正交表
|
||||
- 因字数与状态数刚好符合正交表,直接使用
|
||||
- 因字数与状态数没有符合的正交表
|
||||
- 合并因子的部分取值匹配正交表
|
||||
- 选择因字数和水平数略大于实际值的正交表
|
||||
6. 实际取值替换正交表的状态
|
||||
7. 展开合并的因子取值,空白处确定具体的值(可选)
|
||||
8. 把每一行的各因子水平的组合做为一个测试用例
|
||||
9. 加上你认为可疑且没有在表中出现的组合
|
||||
|
||||
### 5.4正交实验法优缺点
|
||||
|
||||
**优点**
|
||||
|
||||
- 根据正交性从全面试验中挑选出部分有代表性的点进行试验, 这些有代表性的点具备了“均匀分 散,整齐可比”的特点。
|
||||
- 通过使用正交试验法减少了测试用例,合理地减少测试的工时与费用,提高测试用例的有效性。
|
||||
- 正交实验法是一种高效率、快速、经济的实验设计方法。
|
||||
|
||||
**缺点**
|
||||
|
||||
- 对每个状态点同等对待,重点不突出,容易造成在用户不常用的功能或场景中, 花费不少时间进行 测试设计与执行,而在重要路径的使用上反而没有重点测试。
|
||||
- 会存在漏测的风险,生成测试表后需要人工的审核添加一些可疑项
|
||||
|
||||
### 5.5正交实验法使用场景
|
||||
|
||||
**组合查询或搜索,兼容性测试(浏览器/操作系统/分辨率),配置测试**
|
||||
|
||||
|
||||
|
||||
## 6.状态迁移法
|
||||
|
||||
### 6.1状态迁移法概念
|
||||
|
||||
有限状态机
|
||||
|
||||
- 表示有限个状态以及在这些状态之间转移和动作的数学模型
|
||||
- 通过构造能导致状态迁移的事件来测试状态之间的转换
|
||||
|
||||
### 6.2状态迁移法步骤
|
||||
|
||||
1. 画出状态迁移图
|
||||
2. 列出状态 - 事件表
|
||||
3. 画出状态转换树
|
||||
4. 确定测试路径
|
||||
5. 针对每条路径设计测试用例
|
||||
|
||||
### 6.3状态迁移法使用场景
|
||||
|
||||
有工作状态的软件,修改设置/配置,有状态变化的功能测试
|
||||
|
||||
## 7.流程分析法
|
||||
|
||||
### 7.1流程分析法概念
|
||||
|
||||
**流程分析法** 又叫 **场景分析法**,是将软件系统的某个流程看成路径,用路径分析的方法来设计测试用例 关注的重点是流程是否能走下去,每个节点的功能并不关注
|
||||
|
||||
### 7.2流程分析法步骤
|
||||
|
||||
1. 画出流程图
|
||||
2. 确定测试路径
|
||||
- 基本流程 一次性成功的流程
|
||||
- 备选流程 多次反复后才成功的流程
|
||||
- 异常流程 失败的流程
|
||||
3. 针对每条路径至少设计 1 条测试用例
|
||||
|
||||
### 7.3流程分析法使用场景
|
||||
|
||||
业务流程测试,安装流程、卸载流程测试
|
||||
|
||||
## 8.判定表法
|
||||
|
||||
### 8.1判定表概念
|
||||
|
||||
**判定表** 又叫 **决策表**,是分析和表达多种输入条件下系统执行不同动作的工具。它可以把复杂的逻辑关系和多种条件组合的情况表达得既具体又明确。
|
||||
|
||||
等价类划分考虑不同的输入,判定表法考虑针对各种输入的**处理规则**是否正确,目的是测试业务规则。
|
||||
|
||||
### 8.2判定表组成
|
||||
|
||||
**条件桩** 列出了问题的所有条件(**输入**),次序无关紧要
|
||||
|
||||
**条件项** 列出针对它所列条件**(输入)的取值**,即每个条件 **只能取真假两个值**
|
||||
|
||||
**动作桩** 列出所有输入可能的结果项,这些结果项的排列顺序没有约束
|
||||
|
||||
**动作项** 列出在条件项的各种取值情况下应该会有的结果
|
||||
|
||||
**规则** 任一条件组合的特定取值和对应的动作,贯穿条件项和动作项的一列
|
||||
|
||||
### 8.3判定表法步骤
|
||||
|
||||
1. 确定所有输入(条件)和输出(动作)
|
||||
- 每个输入和输出只能有两种取值
|
||||
- 有多种取值的每个取值作为一个条件或动作
|
||||
2. 将所有输入的取值做全排列组合,N个输入有2的N次方列
|
||||
3. 明确每一列对应的动作,形成各个规则,形成判定表
|
||||
4. 对判定表进行化简
|
||||
- 去除无效规则
|
||||
- 合并相似规则(输出与某个输入的取值无关)
|
||||
5. 将每条规则转化为用例
|
||||
|
||||
### 判定表法优缺点
|
||||
|
||||
**优点**
|
||||
|
||||
- 把复杂的问题按各种可能的情况一一列举出来,简单而易于理解,也可避免遗漏
|
||||
|
||||
**缺点**
|
||||
|
||||
- 合并存在漏测的风险
|
||||
|
||||
原因是虽然某个输入条件在输出接口上是无关的, 但是在软件设计上,内部针对这个条件走了不同 的分支
|
||||
|
||||
- 比较繁琐
|
||||
|
||||
### 判定表法使用范围
|
||||
|
||||
- 用于复杂的条件组合,并且不同的组合产生不同结果的时候
|
||||
- 游戏测试
|
||||
|
|
@ -0,0 +1,131 @@
|
|||
---
|
||||
title: 缺陷管理
|
||||
date: 2023-04-14 16:43:50.36
|
||||
updated: 2023-04-15 10:16:15.212
|
||||
url: /archives/que-xian-guan-li
|
||||
categories:
|
||||
- 软件测试
|
||||
tags:
|
||||
- 测试基础
|
||||
---
|
||||
|
||||
## 1.什么是缺陷
|
||||
|
||||
系统或者系统部件中那些导致系统或者部件功能无法使用的问题
|
||||
|
||||
### 缺陷分类
|
||||
|
||||
- 额外实现 与需求规格说明书对比,另外添加了一些功能
|
||||
- 实现缺失 与需求规格说明书对比,少了某些功能
|
||||
- 实现错误 实际结果与预期结果偏差
|
||||
|
||||
### 缺陷、故障、失效的区别
|
||||
|
||||
| 名称 | 英文 | 说明 |
|
||||
| ---- | ---------- | ------------------------------ |
|
||||
| 缺陷 | Defect/Bug | 缺陷是软件内隐藏的问题 |
|
||||
| 故障 | Fault | 缺陷诱发出来产生故障 |
|
||||
| 失效 | Failure | 故障不能很好处理就可能导致失效 |
|
||||
|
||||
## 2.缺陷报告内容
|
||||
|
||||
### 缺陷标识
|
||||
|
||||
一般由缺陷管理系统自动生成
|
||||
|
||||
### 缺陷标题
|
||||
|
||||
在什么地方做了什么操作出现什么错误
|
||||
|
||||
### 缺陷详述
|
||||
|
||||
- 测试环境 预置条件,App类:(手机型号,手机软件版本) Web类(浏览器)
|
||||
- 测试步骤 一般同测试用例
|
||||
- 预期结果 同测试用例
|
||||
- 实际结果 和预期不一样,放截图
|
||||
- 结果分析 对比测试(换手机,换浏览器,换模块),传输数据或日志分析
|
||||
|
||||
**5C原则**
|
||||
|
||||
| 英文 | 中文 | 说明 |
|
||||
| ---------- | ---- | -------------------------------------- |
|
||||
| Concise | 简洁 | 只包含必不可少信息,不包括任何多余内容 |
|
||||
| Correct | 准确 | 每个组成部分的描述准确,不会引起误解 |
|
||||
| Complete | 完整 | 包含复现该缺陷的完整步骤和其他相关信息 |
|
||||
| Clear | 清晰 | 每个组成部分的描述清晰,易于理解 |
|
||||
| Consistent | 一致 | 按照一致的格式书写全部缺陷报告 |
|
||||
|
||||
### 缺陷属性
|
||||
|
||||
#### 严重性
|
||||
|
||||
对软件本身产生的影响
|
||||
|
||||
| 严重性 | 说明 |
|
||||
| ------ | -------------------------- |
|
||||
| 1 致命 | 崩溃、闪退、数据丢失 |
|
||||
| 2 严重 | 影响主要流程的缺陷 |
|
||||
| 3 一般 | 一般的功能,非主流的功能 |
|
||||
| 4 建议 | 界面问题、显示问题、建议类 |
|
||||
|
||||
#### 优先级
|
||||
|
||||
是缺陷被修复的紧急程度
|
||||
|
||||
| 优先级 | 说明 |
|
||||
| ------- | --------------------------------- |
|
||||
| P1 立即 | 致命的问题 立即解决(偶发的除外) |
|
||||
| P2 高 | 严重的问题 高优先级 |
|
||||
| P3 中 | 一般的问题 中优先级 |
|
||||
| P4 低 | 建议的问题 低优先级 |
|
||||
|
||||
#### 分类
|
||||
|
||||
功能问题,性能问题,兼容问题,安全问题 ...
|
||||
|
||||
#### 出现频率
|
||||
|
||||
必然(100%),经常,有时,很少(无法重现)
|
||||
|
||||
#### 状态
|
||||
|
||||
与缺陷流程有关
|
||||
|
||||
### 版本
|
||||
|
||||
被测软件版本号
|
||||
|
||||
### 附件
|
||||
|
||||
截图(有图有真相,更方便描述界面问题),录像,日志(便于开发分析问题),测试数据
|
||||
|
||||
### 报告人
|
||||
|
||||
### 报告日期
|
||||
|
||||
### 指派人
|
||||
|
||||
## 3.缺陷管理工具
|
||||
|
||||
Mantis,Bugzilla,Bugfree,Bugclose,QC,JIRA,禅道,公司自研
|
||||
|
||||
## 4.缺陷管理流程
|
||||
|
||||
- 缺陷管理目的
|
||||
|
||||
缺陷跟踪和解决,缺陷分析和产品度量
|
||||
|
||||
- 缺陷生命周期
|
||||
|
||||
发现-提交-确认-分配-修复-验证-关闭
|
||||
|
||||
- 缺陷管理基本流程
|
||||
|
||||
1. 测试人员发现缺陷并提交 Bug,状态 New
|
||||
2. 开发人员接受 Bug,状态 Open
|
||||
3. 开发人员解决 Bug,状态 Fixed
|
||||
4. 测试人员验证 Bug
|
||||
5. 如果解决,状态 Closed
|
||||
6. 如果未解决,状态 Reopen
|
||||
|
||||

|
||||
|
|
@ -0,0 +1,35 @@
|
|||
# 安装包安装
|
||||
|
||||
## 下载
|
||||
|
||||
CDN 下载地址:https://cos-sdk-archive-1253960454.file.myqcloud.com/cosfs/v1.0.21/cosfs_1.0.21-ubuntu20.04_amd64.deb
|
||||
|
||||
## 安装
|
||||
|
||||
```
|
||||
sudo dpkg -i cosfs_1.0.21-ubuntu20.04_amd64.deb
|
||||
```
|
||||
|
||||
## 使用方法
|
||||
|
||||
配置密钥文件
|
||||
|
||||
```
|
||||
sudo su # 切换到 root 身份,以修改 /etc/passwd-cosfs 文件;如果已经为 root 用户,无需执行该条命令。
|
||||
echo <BucketName-APPID>:<SecretId>:<SecretKey> > /etc/passwd-cosfs
|
||||
chmod 640 /etc/passwd-cosfs
|
||||
```
|
||||
|
||||
运行工具
|
||||
|
||||
```
|
||||
cosfs <BucketName-APPID> <MountPoint> -ourl=http://cos.<Region>.myqcloud.com -odbglevel=info -oallow_other
|
||||
```
|
||||
|
||||
示例
|
||||
|
||||
```
|
||||
mkdir -p /mnt/cosfs
|
||||
cosfs examplebucket-1250000000 /mnt/cosfs -ourl=http://cos.ap-guangzhou.myqcloud.com -odbglevel=info -onoxattr -oallow_other
|
||||
```
|
||||
|
||||
|
|
@ -0,0 +1,492 @@
|
|||
---
|
||||
title: 腾讯云COS配置示例
|
||||
date: 2022-05-31 19:44:00.86
|
||||
updated: 2022-12-05 22:45:03.322
|
||||
url: /archives/coscmdconfigmd
|
||||
categories:
|
||||
- Tools
|
||||
tags:
|
||||
- Tools
|
||||
---
|
||||
|
||||
安装Python
|
||||
|
||||
官网:https://www.python.org/downloads/source/
|
||||
|
||||
以 **Python3.6.1** 版本为例:
|
||||
|
||||
```
|
||||
# tar -zxvf Python-3.6.1.tgz
|
||||
# cd Python-3.6.1
|
||||
# ./configure
|
||||
# make && make install
|
||||
```
|
||||
|
||||
检查 Python3 是否正常可用:
|
||||
|
||||
```
|
||||
# python3 -V
|
||||
Python 3.6.1
|
||||
```
|
||||
|
||||
#### 通过 pip 安装 coscmd
|
||||
|
||||
```
|
||||
pip install coscmd
|
||||
```
|
||||
|
||||
更新
|
||||
|
||||
```
|
||||
pip install coscmd -U
|
||||
```
|
||||
|
||||
生成配置文件
|
||||
|
||||
```
|
||||
coscmd config -a AKIDc3E8m9G7i5C3dwykFTQ6XhaCYdRyGG0S -s EApFPIvHMBk23nHUR7WeW7SWIoyrToth -b sh-data-1308339952 -r ap-shanghai
|
||||
```
|
||||
|
||||
常用命令
|
||||
|
||||
### Debug 模式执行命令
|
||||
|
||||
在各命令前加上 `-d` 或者 `--debug`,在命令执行的过程中,会显示详细的操作信息 。示例如下:
|
||||
|
||||
```
|
||||
coscmd -d upload <localpath> <cospath>
|
||||
```
|
||||
|
||||
### Silence 模式执行命令
|
||||
|
||||
在各命令前加上 `-s` 或者 `--silence`,在命令执行的过程中,将不会再输出任何信息
|
||||
|
||||
```
|
||||
coscmd -s upload <localpath> <cospath>
|
||||
```
|
||||
|
||||
## 常用存储桶命令
|
||||
|
||||
### 创建存储桶
|
||||
|
||||
> 说明:
|
||||
>
|
||||
> 执行创建存储桶命令时,请携带参数 `-b <BucketName-APPID>` 指定存储桶名称和 `-r <Region>` 指定所属地域。若直接执行 coscmd createbucket,则会报错,原因是不指定存储桶名称和所属地域,则相当于对已存在的存储桶(即配置参数时所填的存储桶)进行创建。
|
||||
|
||||
- 命令格式
|
||||
|
||||
```plaintext
|
||||
coscmd -b <BucketName-APPID> createbucket
|
||||
```
|
||||
|
||||
- 操作示例-创建一个名称为 examplebucket,所属地域为北京的存储桶
|
||||
|
||||
```plaintext
|
||||
coscmd -b examplebucket-1250000000 -r ap-beijing createbucket
|
||||
```
|
||||
|
||||
### 删除存储桶
|
||||
|
||||
> 说明:
|
||||
>
|
||||
> `coscmd deletebucket` 的用法仅对配置参数时的存储桶有效。建议配合 `-b <BucketName-APPID>` 指定 Bucket 和 `-r <region>` 指定 Region 使用。
|
||||
|
||||
- 命令格式
|
||||
|
||||
```plaintext
|
||||
coscmd -b <BucketName-APPID> deletebucket
|
||||
```
|
||||
|
||||
- 操作示例 - 删除空的存储桶
|
||||
|
||||
```plaintext
|
||||
coscmd -b examplebucket-1250000000 -r ap-beijing deletebucket
|
||||
```
|
||||
|
||||
- 操作示例 - 强制删除非空的存储桶
|
||||
|
||||
```plaintext
|
||||
coscmd -b examplebucket-1250000000 -r ap-beijing deletebucket -f
|
||||
```
|
||||
|
||||
> 注意:
|
||||
>
|
||||
> 使用 `-f` 参数则会强制删除该存储桶,包括所有文件、开启版本控制之后历史文件夹、上传产生的碎片,请谨慎操作。
|
||||
|
||||
## 常用对象命令
|
||||
|
||||
### 上传文件
|
||||
|
||||
- 上传文件命令格式
|
||||
|
||||
```plaintext
|
||||
coscmd upload <localpath> <cospath>
|
||||
```
|
||||
|
||||
> 注意:
|
||||
>
|
||||
> 请将 "<>" 中的参数替换为您需要上传的本地文件路径(localpath),以及 COS 上存储的路径(cospath)。
|
||||
|
||||
- 操作示例 - 将 D 盘的 picture.jpg 文件上传到 COS 的 doc 目录下
|
||||
|
||||
```plaintext
|
||||
coscmd upload D:/picture.jpg doc/
|
||||
```
|
||||
|
||||
- 操作示例 - 将 D 盘的 doc 文件夹下的 picture.jpg 文件上传到 COS 的 doc 目录下
|
||||
|
||||
```plaintext
|
||||
coscmd upload D:/doc/picture.jpg doc/
|
||||
```
|
||||
|
||||
- 操作示例 - 指定对象类型,上传一个归档类型的文件到 COS 的 doc 目录下
|
||||
|
||||
```plaintext
|
||||
coscmd upload D:/picture.jpg doc/ -H "{'x-cos-storage-class':'Archive'}"
|
||||
```
|
||||
|
||||
> 注意:
|
||||
>
|
||||
> 使用 -H 参数设置 HTTP header 时,请务必保证格式为 JSON,示例:`coscmd upload -H "{'x-cos-storage-class':'Archive','Content-Language':'zh-CN'}" <localpath> <cospath>`。更多头部可参见 [PUT Object](https://cloud.tencent.com/document/product/436/7749) 文档。
|
||||
|
||||
- 操作示例 - 设置 meta 元属性,上传一个文件到 COS 的 doc 目录下
|
||||
|
||||
```plaintext
|
||||
coscmd upload D:/picture.jpg doc/ -H "{'x-cos-meta-example':'example'}"
|
||||
```
|
||||
|
||||
### 上传文件夹
|
||||
|
||||
- 上传文件夹命令格式
|
||||
|
||||
```plaintext
|
||||
coscmd upload -r <localpath> <cospath>
|
||||
```
|
||||
|
||||
> 注意:
|
||||
>
|
||||
> Windows 用户推荐在系统自带的 cmd 工具或 PowerShell 上使用 COSCMD 的 upload 命令,其他工具(如 git bash)对命令路径的解析策略与 PowerShell 不同,可能会导致用户的文件被上传到错误的路径上去。
|
||||
|
||||
- 操作示例 - 将 D 盘的 doc 文件夹及其文件上传到 COS 根路径
|
||||
|
||||
```plaintext
|
||||
coscmd upload -r D:/doc /
|
||||
```
|
||||
|
||||
- 操作示例 - 将 D 盘的 doc 文件夹及其文件上传到 COS 的 doc 路径
|
||||
|
||||
```plaintext
|
||||
coscmd upload -r D:/doc doc
|
||||
```
|
||||
|
||||
- 操作示例 - 同步上传,跳过 md5、文件大小相同的同名文件
|
||||
|
||||
```plaintext
|
||||
coscmd upload -rs D:/doc doc
|
||||
```
|
||||
|
||||
> 注意:
|
||||
>
|
||||
> 使用 -s 参数可以使用同步上传,跳过上传 md5 一致的文件(COS 上的原文件必须是由 1.8.3.2 版本之后的 COSCMD 上传的,默认带有 x-cos-meta-md5 的 header)。
|
||||
|
||||
- 操作示例 - 同步上传,跳过文件大小相同的同名文件
|
||||
|
||||
```plaintext
|
||||
coscmd upload -rs --skipmd5 D:/doc doc
|
||||
```
|
||||
|
||||
> 注意:
|
||||
>
|
||||
> 使用 -s 参数可以使用同步上传,且带上 --skipmd5 参数后,将只对比同名文件的大小,如果大小相同则跳过上传。
|
||||
|
||||
- 操作示例 - 同步上传,并删除 “D 盘 doc 文件夹中已经删除的文件”
|
||||
|
||||
```plaintext
|
||||
coscmd upload -rs --delete D:/doc /
|
||||
```
|
||||
|
||||
- 操作示例 - D 盘 doc 文件夹中 .txt 和 .doc 的后缀文件选择忽略上传
|
||||
|
||||
```plaintext
|
||||
coscmd upload -rs D:/doc / --ignore *.txt,*.doc
|
||||
```
|
||||
|
||||
> 注意:
|
||||
>
|
||||
> 在上传文件夹时,使用 `--ignore` 参数可以忽略某一类文件,使用 `--include` 参数可以过滤某一类文件,支持 shell 通配规则,支持多条规则,用逗号`,`分隔。当忽略一类后缀时,必须最后要输入`,` 或者加入`""`。
|
||||
|
||||
- 操作示例 - D 盘 doc 文件夹中 .txt 和 .doc 的后缀文件上传
|
||||
|
||||
```plaintext
|
||||
coscmd upload -rs D:/doc / --include *.txt,*.doc
|
||||
```
|
||||
|
||||
> 注意:
|
||||
>
|
||||
>
|
||||
>
|
||||
> - 当上传大于10MB的文件,COSCMD 即采用分块上传方式,命令用法和简单上传一致,即 `coscmd upload <localpath> <cospath>`。
|
||||
> - COSCMD 支持大文件断点上传功能;当分块上传大文件失败时,重新上传该文件只会上传失败的分块,而不会从头开始(请保证重新上传的文件的目录以及内容和上传的目录保持一致)。
|
||||
> - COSCMD 分块上传时会对每一块进行 MD5 校验。
|
||||
> - COSCMD 上传默认会携带 `x-cos-meta-md5` 的头部,值为该文件的 md5 值,如果带上 --skipmd5 参数则不携带该头部。
|
||||
|
||||
### 查询文件列表
|
||||
|
||||
查询命令如下:
|
||||
|
||||
- 命令格式
|
||||
|
||||
```plaintext
|
||||
coscmd list <cospath>
|
||||
```
|
||||
|
||||
- 操作示例 - 递归查询该存储桶下 doc/ 前缀下所有的文件列表
|
||||
|
||||
```plaintext
|
||||
coscmd list doc/
|
||||
```
|
||||
|
||||
- 操作示例 - 递归查询该存储桶下所有的文件列表、文件数量和文件大小
|
||||
|
||||
```plaintext
|
||||
coscmd list -ar
|
||||
```
|
||||
|
||||
- 操作示例 - 递归查询 examplefolder 前缀的所有文件列表
|
||||
|
||||
```plaintext
|
||||
coscmd list examplefolder/ -ar
|
||||
```
|
||||
|
||||
- 操作示例 - 查询该存储桶下所有文件的历史版本
|
||||
|
||||
```plaintext
|
||||
coscmd list -v
|
||||
```
|
||||
|
||||
> 说明:
|
||||
>
|
||||
>
|
||||
>
|
||||
> - 请将"<>"中的参数替换为您需要查询文件列表的 COS 上文件的路径(cospath)。`<cospath>` 为空默认查询当前存储桶根目录。
|
||||
> - 使用 `-a` 查询全部文件。
|
||||
> - 使用 `-r` 递归查询,并且会在末尾返回列出文件的数量和大小之和。
|
||||
> - 使用 `-n num` 设置查询数量的最大值。
|
||||
|
||||
### 查看文件信息
|
||||
|
||||
命令如下:
|
||||
|
||||
- 命令格式
|
||||
|
||||
```plaintext
|
||||
coscmd info <cospath>
|
||||
```
|
||||
|
||||
- 操作示例 - 查看 doc/picture.jpg 的元信息
|
||||
|
||||
```plaintext
|
||||
coscmd info doc/picture.jpg
|
||||
```
|
||||
|
||||
> 说明:
|
||||
>
|
||||
> 请将"<>"中的参数替换为您需要显示的 COS 上文件的路径(cospath)。
|
||||
|
||||
### 下载文件或文件夹
|
||||
|
||||
#### 下载文件命令格式
|
||||
|
||||
|
||||
|
||||
```plaintext
|
||||
coscmd download <cospath> <localpath>
|
||||
```
|
||||
|
||||
|
||||
|
||||
> 注意:
|
||||
>
|
||||
> 请将 "<>" 中的参数替换为您需要下载的 COS 上文件的路径(cospath),以及本地存储路径(localpath)。
|
||||
|
||||
- 操作示例 - 下载 COS 上的 doc/picture.jpg 到 D:/picture.jpg
|
||||
|
||||
```plaintext
|
||||
coscmd download doc/picture.jpg D:/picture.jpg
|
||||
```
|
||||
|
||||
- 操作示例 - 下载 COS 上的 doc/picture.jpg 到 D 盘
|
||||
|
||||
```plaintext
|
||||
coscmd download doc/picture.jpg D:/
|
||||
```
|
||||
|
||||
- 操作示例 - 下载一个带有版本 ID 的 picture.jpg 文件到 D 盘
|
||||
|
||||
```plaintext
|
||||
coscmd download picture.jpg --versionId MTg0NDUxMzc2OTM4NTExNTg7Tjg D:/
|
||||
```
|
||||
|
||||
#### 下载文件夹命令格式
|
||||
|
||||
|
||||
|
||||
```plaintext
|
||||
coscmd download -r <cospath> <localpath>
|
||||
```
|
||||
|
||||
|
||||
|
||||
- 操作示例 - 下载 doc 目录为 D:/folder/doc
|
||||
|
||||
```plaintext
|
||||
coscmd download -r doc D:/folder/
|
||||
```
|
||||
|
||||
- 操作示例 - 下载根目录文件,但跳过根目录下的 doc 目录
|
||||
|
||||
```plaintext
|
||||
coscmd download -r / D:/ --ignore doc/*
|
||||
```
|
||||
|
||||
- 操作示例 - 覆盖下载当前存储桶根目录下所有的文件
|
||||
|
||||
```plaintext
|
||||
coscmd download -rf / D:/examplefolder/
|
||||
```
|
||||
|
||||
> 注意:
|
||||
>
|
||||
> 若本地存在同名文件,则会下载失败,需要使用 `-f` 参数覆盖本地文件。
|
||||
|
||||
- 操作示例 - 同步下载当前 bucket 根目录下所有的文件,跳过 md5校验相同的同名文件
|
||||
|
||||
```plaintext
|
||||
coscmd download -rs / D:/examplefolder
|
||||
```
|
||||
|
||||
> 注意:
|
||||
>
|
||||
> 使用 `-s` 或者 `--sync` 参数,可以在下载文件夹时跳过本地已存在的相同文件(前提是下载的文件是通过 COSCMD 的 upload 接口上传的,文件携带有 `x-cos-meta-md5` 头部)。
|
||||
|
||||
- 操作示例 - 同步下载当前 bucket 根目录下所有的文件,跳过文件大小相同的同名文件
|
||||
|
||||
```plaintext
|
||||
coscmd download -rs --skipmd5 / D:/examplefolder
|
||||
```
|
||||
|
||||
- 操作示例 - 同步下载当前 bucket 根目录下所有的文件,同时删除“云上删除但本地未删除的文件”
|
||||
|
||||
```plaintext
|
||||
coscmd download -rs --delete / D:/examplefolder
|
||||
```
|
||||
|
||||
- 操作示例 - 忽略 .txt 和 .doc 的后缀文件
|
||||
|
||||
```plaintext
|
||||
coscmd download -rs / D:/examplefolder --ignore *.txt,*.doc
|
||||
```
|
||||
|
||||
> 注意:
|
||||
>
|
||||
> 在下载文件夹时,使用 `--ignore` 参数可以忽略某一类文件,使用 `--include` 参数可以过滤某一类文件,支持 shell 通配规则,支持多条规则,用逗号`,`分隔。当忽略一类后缀时,必须最后要输入`,`或者使用双引号`""`。
|
||||
|
||||
- 操作示例 - 过滤 .txt 和 .doc 的后缀文件
|
||||
|
||||
```plaintext
|
||||
coscmd download -rs / D:/examplefolder --include *.txt,*.doc
|
||||
```
|
||||
|
||||
> 注意:
|
||||
>
|
||||
> 老版本的 mget 接口已经废除,download 接口使用分块下载,请使用 download 接口。
|
||||
|
||||
### 获取带签名的下载 URL
|
||||
|
||||
- 命令格式
|
||||
|
||||
```plaintext
|
||||
coscmd signurl <cospath>
|
||||
```
|
||||
|
||||
- 操作示例 - 生成 doc/picture.jpg 路径带签名的 URL
|
||||
|
||||
```plaintext
|
||||
coscmd signurl doc/picture.jpg
|
||||
```
|
||||
|
||||
- 操作示例 - 生成 doc/picture.jpg 路径带 100s 签名的 URL
|
||||
|
||||
```plaintext
|
||||
coscmd signurl doc/picture.jpg -t 100
|
||||
```
|
||||
|
||||
> 说明:
|
||||
>
|
||||
>
|
||||
>
|
||||
> - 请将 "<>" 中的参数替换为您需要获取下载 URL 的 COS 上文件的路径(cospath)。
|
||||
> - 使用 `-t time` 设置该 URL 中签名的有效时间(单位为秒), 默认为10000s。
|
||||
|
||||
### 删除文件或文件夹
|
||||
|
||||
#### 删除文件命令格式
|
||||
|
||||
|
||||
|
||||
```plaintext
|
||||
coscmd delete <cospath>
|
||||
```
|
||||
|
||||
|
||||
|
||||
> 注意:
|
||||
>
|
||||
> 请将"<>"中的参数替换为您需要删除的 COS 上文件的路径(cospath),工具会提示用户是否确认进行删除操作。
|
||||
|
||||
- 操作示例 - 删除 doc/exampleobject.txt
|
||||
|
||||
```plaintext
|
||||
coscmd delete doc/exampleobject.txt
|
||||
```
|
||||
|
||||
- 操作示例 - 删除带有版本 ID 的文件
|
||||
|
||||
```plaintext
|
||||
coscmd delete doc/exampleobject.txt --versionId MTg0NDUxMzc4ODA3NTgyMTErEWN
|
||||
```
|
||||
|
||||
#### 删除文件夹命令格式
|
||||
|
||||
|
||||
|
||||
```plaintext
|
||||
coscmd delete -r <cospath>
|
||||
```
|
||||
|
||||
|
||||
|
||||
- 操作示例 - 删除 doc 目录
|
||||
|
||||
```plaintext
|
||||
coscmd delete -r doc
|
||||
```
|
||||
|
||||
- 操作示例 - 删除 folder/doc 目录
|
||||
|
||||
```plaintext
|
||||
coscmd delete -r folder/doc
|
||||
```
|
||||
|
||||
- 操作示例 - 删除 doc 文件夹下的所有版本控制文件
|
||||
|
||||
```plaintext
|
||||
coscmd delete -r doc/ --versions
|
||||
```
|
||||
|
||||
> 说明:
|
||||
>
|
||||
>
|
||||
>
|
||||
> - 批量删除需要输入 `y` 确定,使用 `-f` 参数则可以跳过确认直接删除。
|
||||
> - 需注意,执行删除文件夹命令,将会删除当前文件夹及其文件。但删除版本控制的文件,需要指定版本 ID 进行删除。
|
||||
|
|
@ -0,0 +1,234 @@
|
|||
---
|
||||
title: 计算机网络
|
||||
date: 2021-05-08 23:14:38.0
|
||||
updated: 2023-03-25 19:10:27.55
|
||||
url: /archives/base
|
||||
categories:
|
||||
tags:
|
||||
- Base
|
||||
---
|
||||
|
||||
# 计算机网络
|
||||
|
||||
## 计算机网络的拓扑结构
|
||||
|
||||
#### 总线型
|
||||
|
||||
- 网络的拓扑结构是指网络中通信线路和站 点的几何排列形式。
|
||||
|
||||
- 总线型:只有单一的通信线路(称为总线) ,所有站点直接连接到这条总线上。
|
||||
|
||||
- 优点主要是结构简单、布线容易、成本低 廉、易于扩展
|
||||
|
||||
- 缺点是总线的故障会导致网络瘫痪
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
#### 星型
|
||||
- 有一个惟一的转接结点,各站点通过点到点的链路直接连接到转接
|
||||
- 结点上。
|
||||
- 优点是结构简单、易于实现和便于管理。
|
||||
- 缺点是转接结点的故障会导致网络瘫痪。
|
||||
- 应用:小型局域网,可以和总线型混合使用。
|
||||

|
||||
|
||||
#### 树型
|
||||
- 结点按层次进行连接。信息交换主要在上下层结点之间。
|
||||
- 树型网络中除了叶子结点之外的所有非终端结点都是转接结点。
|
||||
- 优点是组网灵活、易于扩展。
|
||||
- 缺点是对根结点的依赖性太大,相邻或同层结点之间不能直接传递信息。
|
||||

|
||||
|
||||
#### 环型
|
||||
- 各个站点通过通信线路连接成一个闭合的环。
|
||||
- 优点是结构简单、传输延时确定。
|
||||
- 缺点是扩展、维护不便
|
||||
- 应用:地铁、高速公路、发电、油厂、气厂、矿山、冶金
|
||||

|
||||
## 网络传输的介质
|
||||
### 分类
|
||||

|
||||
|
||||
|
||||
#### 光纤
|
||||
- 通信容量大,传输宽度比电缆线或者铜线的宽度大很多
|
||||
- 应用:海底光缆、核心网(跨国)骨干网等
|
||||
|
||||

|
||||
|
||||
## 计算机网络的分类
|
||||
#### Internet 和 Intranet.1
|
||||
- 定义:Internet,国际互联网。它是由那些使用公用语言互相通信的计算机连接而成的全球网络。
|
||||
- 起源:美国国防部高级研究计划局的前身ARPA建立的ARPAnet,该网于1969年投入使用,具有里程碑意义。
|
||||
- 目的:允许世界上数以亿计的人们进行通讯和共享信息。
|
||||
|
||||
#### Internet 和 Intranet.2
|
||||
- 定义:Intranet是企业内部网。
|
||||
- 特点:
|
||||
- 相对封闭的网络环境。
|
||||
- 防火墙保护
|
||||
- 有权限控制
|
||||
- 目的:使企业内部的秘密或敏感信息受到保护。
|
||||
|
||||
#### 三种网络体系结构
|
||||
- C/S(Client/Server)架构
|
||||
微信、QQ、抖音
|
||||
- B/S(Browser/Server)架构
|
||||
浏览器、WWW浏览器、服务器端实现事务逻辑
|
||||
- P2P(Point-to-Point)架构
|
||||
点对点、飞秋
|
||||
|
||||
#### B/S 模式优缺点
|
||||
优点
|
||||
• 具有分布性特点,可以随时随地进行查询、浏览等业务处理。
|
||||
• 业务扩展简单方便,通过增加网页即可增加服务器功能。
|
||||
• 维护简单方便,只需要改变网页,即可实现所有用户的同步更新。
|
||||
缺点
|
||||
• 个性化特点明显降低,无法实现具有个性化的功能要求。
|
||||
• 操作是以鼠标为最基本的操作方式,无法满足快速操作的要求。
|
||||
• 页面动态刷新,响应速度明显降低。
|
||||
|
||||
#### C/S 模式优缺点
|
||||
优点:
|
||||
• 客户端与服务器的直接相连,响应速度快。
|
||||
• 界面多样性,满足客户个性化要求。
|
||||
• 能实现复杂的业务流程。
|
||||
• 面对有限群体,高机密性
|
||||
缺点 :
|
||||
• 客户端安装程序,不能够实现快速部署安装和配置。
|
||||
• 兼容性差,各操作系统、多版本都要面对。
|
||||
• 升级成本较高。
|
||||
|
||||
|
||||
|
||||
## TCP/IP协议
|
||||
#### 网络协议模型 – OSI参考模型
|
||||

|
||||
|
||||
#### 封装和解封装
|
||||

|
||||
|
||||
#### OSI参考模型 – 物理层
|
||||
- 作用:为传输数据所需要的物理链路进行创建、维持、拆除。
|
||||
- 常见的物理层设备是:中继器、集线器
|
||||
- 这一层,数据的单位称为比特(bit)。
|
||||

|
||||
|
||||
#### OSI参考模型 – 数据链路层
|
||||
它为网络层提供服务,在不可靠的物理介质上提供可靠的传输。
|
||||
- 作用包括:物理地址寻址、数据的成帧、流量控制、数据的检错、重发等。
|
||||
- 常见的链路层设备是:二层交换机、网桥。
|
||||
- 这一层,数据的单位称为帧(frame)
|
||||

|
||||
|
||||
#### OSI参考模型 – 网络层
|
||||
使数据路由经过大型网络。
|
||||
- 这一层,数据的单位称为数据包(packet)。
|
||||
- 网络层主要设备:路由器
|
||||

|
||||
|
||||
#### OSI参考模型 – 传输层
|
||||
- 提供终端到终端的可靠连接。
|
||||
- 这一层,数据的单位称为数据段(segment)。
|
||||

|
||||
|
||||
#### OSI参考模型 – 会话、表示、应用层
|
||||
- 会话层:管理主机之间的会话进程,即负责建立、管理、终止进程之间的会话。
|
||||
- 表示层:编码、加密解密、压缩
|
||||
- 应用层:DNS、HTTP、邮件服务、文件传送服务等
|
||||

|
||||
|
||||
#### 网络协议模型 – TCP/IP模型
|
||||

|
||||
- 网络访问层
|
||||
- Internet层
|
||||
- 传输层
|
||||
- 应用层
|
||||
- TCP/IP----“transmission Control Protocol/Internet Protocol” 传输控制协议/互联网络协议
|
||||
|
||||
#### IP协议
|
||||
- IP ---Internet Protocol,是Internet层(网络层)的协议
|
||||
- 用于将多个包交换网络连接起来的,在源地址和目的地址之间传送数据报。
|
||||
- IP协议头
|
||||
- IP地址:
|
||||

|
||||
|
||||
#### Ip地址的规则
|
||||
- IPV4地址由32位二进制数组成
|
||||
- 以XXX.XXX.XXX.XXX形式表现,例如:192.168.22.33
|
||||
- 每组XXX代表小于或等于255的10进制数,该表示方法称为点分十进制
|
||||
- IPv6地址为128位长,但通常写作8组,每组四个十六进制数的形式。例如:2001:0db8:85a3:08d3:1319:8a2e:0370:7344
|
||||
|
||||
#### TCP\IP协议 – TCP协议
|
||||
- 传输层上的协议
|
||||
- TCP 协议提供了一种端到端的、基于连接的、可靠的通信服务。
|
||||
- TCP协议头
|
||||

|
||||
|
||||
#### TCP协议 – 三次握手
|
||||
- 建立TCP需要三次握手才能建立,而断开连接则需要四次挥手。
|
||||

|
||||
|
||||
#### TCP协议 – 四次挥手
|
||||
- TCP链接是全双工的,因此每个方向上都必须要关闭。
|
||||

|
||||
|
||||
|
||||
## 应用层HTTP协议
|
||||
#### 应用层HTTP协议
|
||||
- HTTP ---hypertext transport protocol;
|
||||
- 定义: 规定了浏览器和www服务器之间互相通信的规则,通过Internet传送www文档的数据传送协议。
|
||||
- 应用层协议
|
||||

|
||||
|
||||
#### HTTP的特点和原理
|
||||
- HTTP 协议是一种请求-应答式的协议。
|
||||
- 最显著的特点是客户端发送的每次请求都需要服务器回送响应,在请求结束后,会主动释放连接。从建立连接到关闭连接的过程称为“一次连接”。
|
||||
- 原理:
|
||||
- 短连接:用完就释放。
|
||||
- 需要不断向服务器发起连接请求来保持在线状态。
|
||||
- 若服务器长时间无法收到客户端的请求,则认为客户端“下线”
|
||||
- 若客户端长时间无法收到服务器的回复,则认为网络已经断开。
|
||||
|
||||
#### HTTP协议 – Http请求
|
||||
- 请求:Request,由客户端发送给服务器端
|
||||
- 请求分类:GET和POST请求
|
||||
- GET请求主要是数据的获取
|
||||
- POST请求主要是数据的提交
|
||||
- Fiddler的GET和POST请求介绍
|
||||
|
||||
#### GET请求
|
||||

|
||||
|
||||
#### POST请求
|
||||

|
||||
|
||||
#### HTTP协议 – Http响应
|
||||
HTTP协议 – Http响应
|
||||
- 响应:Response,由服务器端返回给客户端
|
||||
- 响应包含 正常的响应 和 异常的响应。
|
||||
- HTTP协议通过响应的状态码来进行定义:1xx, 2xx, 3xx(正常),4xx, 5xx(异常)
|
||||
|
||||
|
||||
## Session和Cookie介绍
|
||||
|
||||
#### HTTP协议 – Session和Cookie.1
|
||||
- Http协议的特点:无连接、无状态
|
||||
- Cookie是服务器暂存放在用户计算机上的一些资料,好让服务器用来辨认用户的计算机。
|
||||
- Session:会话,客户端和服务器之间的会话
|
||||

|
||||
|
||||
#### HTTP协议 –Cookie
|
||||
• Cookie应用:
|
||||
- 保存用户的登录信息,例如用户名和密码
|
||||
- 用户在上一次浏览网站时的表单输入和操作步骤
|
||||
|
||||
#### HTTP协议 – Session
|
||||
- Session是客户端与服务器之间的会话。
|
||||
- 当访问网站时,服务器会标示该访问者,给它一个Session ID,当他离开的时候(也就是关闭浏览器的时候)就删除这个Session ID。
|
||||
- Session ID以响应的方式传递给客户端,客户端在后续的请求中将该Session ID值包含在Cookie字段中回传给服务器,服务器就可以用来对客户端的身份进行验证了。
|
||||

|
||||
|
||||
|
||||
|
|
@ -0,0 +1,9 @@
|
|||
---
|
||||
title: 请求详解
|
||||
date: 2022-09-22 21:03:53.581
|
||||
updated: 2022-09-30 21:47:24.739
|
||||
url: /archives/请求详解
|
||||
categories:
|
||||
tags:
|
||||
---
|
||||
|
||||
|
|
@ -0,0 +1,118 @@
|
|||
---
|
||||
title: 软件测试
|
||||
date: 2023-02-21 20:14:58.891
|
||||
updated: 2023-04-11 18:27:44.423
|
||||
url: /archives/testbase01
|
||||
categories:
|
||||
- 软件测试
|
||||
tags:
|
||||
- 测试基础
|
||||
---
|
||||
|
||||
# 测试基础
|
||||
|
||||
## 什么是软件测试
|
||||
|
||||
**软测定义:**软件测试是对软件的认知活动。软件测试不仅仅是发现缺陷,测试不一定要运行软件。
|
||||
|
||||
**软测目的:**
|
||||
|
||||
- 证明 证明软件可用
|
||||
- 检测 检测软件的质量,发现软件的缺陷,错误和不足
|
||||
- 预防 预防缺陷的产生
|
||||
|
||||
**不同阶段测试的目的:**
|
||||
|
||||
- 项目早期 预防缺陷的产生
|
||||
- 1. 项目计划评审
|
||||
- 2. 需求文档评审
|
||||
- 3. 设计文档的评审
|
||||
- 4. 测试用例文档的评审
|
||||
- 项目中期 先发现严重的缺陷,让软件尽快稳定
|
||||
- 项目后期 证明软件的功能都实现,可用正常使用
|
||||
|
||||
## 什么是缺陷
|
||||
|
||||
### 缺陷、故障、失效的区别
|
||||
|
||||
- **缺陷是软件内隐藏的问题**
|
||||
- 缺陷诱发出来产生故障
|
||||
- 故障不能很好处理就可能导致失效
|
||||
|
||||
### 缺陷分类
|
||||
|
||||
- 额外实现 做多了,需求里没有的功能实现了
|
||||
- 实现缺失 做少了,需求里有的功能没有实现
|
||||
- 实现错误 做错了,需求里的功能实现了,但和预期不一致
|
||||
|
||||
|
||||
|
||||
## 软件生命周期
|
||||
|
||||
### 计划
|
||||
|
||||
项目经理输出项目计划
|
||||
|
||||
主要内容:项目目标,大致需求,人员安排,时间安排等等内容
|
||||
|
||||
### 需求分析
|
||||
|
||||
产品/需求输出**需求规格说明书(SRS)**
|
||||
|
||||
- 进一步确定用户的需求
|
||||
- 软件功能的具体描述
|
||||
- 解决系统 **做什么** 的问题
|
||||
|
||||
### 设计
|
||||
|
||||
架构师输出**概要设计文档**,资深开发输出**详细设计文档**
|
||||
|
||||
- 软件-子系统-模块-函数
|
||||
- 解决系统 **怎么做** 的问题
|
||||
|
||||
### 编码
|
||||
|
||||
开发实现编写代码实现产品功能
|
||||
|
||||
### 测试
|
||||
|
||||
测试输出**测试计划、测试方案、测试用例、测试结果、缺陷报告、测试报告**
|
||||
|
||||
- 检查软件的实现是否和需求一致
|
||||
- 检查软件的实现是否有遗漏
|
||||
|
||||
### 运维
|
||||
|
||||
运维工程师:
|
||||
|
||||
技术支持:系统的安装,部署,升级,问题排查
|
||||
|
||||
# 瀑布模型
|
||||
|
||||
**串行的顺序流程**
|
||||
|
||||
- 从计划到维护
|
||||
- 重视文档,上一阶段输出的文档是下一阶段的输入。
|
||||
- 一个阶段完成,资源会大部分释放给其他项目。一般资源是多项目共享。
|
||||
- 一个阶段发现的问题,返回上一个阶段解决。
|
||||
- 适合需求在项目初始阶段可以明确的周期较长的项目
|
||||
- 可以运行在软件在项目后期才能拿到
|
||||
|
||||
分成三个阶段:
|
||||
|
||||
- 定义阶段 计划和需求分析
|
||||
- 开发阶段 设计,编码和测试
|
||||
- 维护阶段 运行维护
|
||||
|
||||

|
||||
|
||||
|
||||
## 螺旋模型
|
||||
|
||||
**串行的顺序流程**
|
||||
|
||||
- 分阶段实现功能,每个功能的开发都是采用瀑布模型
|
||||
- 较早可以看到能运行的软件
|
||||
- 一个原型完成后,经过风险评估进行进行下一个原型的开发
|
||||
|
||||

|
||||
|
|
@ -0,0 +1,116 @@
|
|||
---
|
||||
title: 软件质量
|
||||
date: 2023-04-12 14:59:14.363
|
||||
updated: 2023-04-12 14:59:14.363
|
||||
url: /archives/ruanjianzhiliang
|
||||
categories:
|
||||
- 软件测试
|
||||
tags:
|
||||
- 测试基础
|
||||
---
|
||||
|
||||
## 什么是软件质量
|
||||
|
||||
### 质量的定义
|
||||
|
||||
质量是实体的各种特性满足需求的程度
|
||||
|
||||
**三要素**
|
||||
|
||||
- 实体:产品(硬件产品,软件产品,软硬件结合的产品)和服务
|
||||
- 特性:多角度评价:功能,性能,易用性,安全性,可靠性 ...
|
||||
- 需求
|
||||
|
||||
### 软件质量的定义
|
||||
|
||||
软件质量是软件的实体特性对需求的满足程度
|
||||
|
||||
#### 软件质量的三个层次
|
||||
|
||||
- 内部质量和外部质量:对需求规格的满足
|
||||
- 验收质量:对用户需求(显式)的满足
|
||||
- 使用质量:对用户实际需求(显式和隐式)的满足
|
||||
|
||||
#### 软件质量铁三角
|
||||
|
||||
- 组织:公司或者企业的组织结构
|
||||
|
||||
- 技术:开发技术、测试技术
|
||||
|
||||
- 流程:大流程:项目管理流程、小流程:缺陷管理流程
|
||||
|
||||
## 软件质量模型
|
||||
|
||||
从多个不同角度看待软件,分 6 大特性和 27 子特性
|
||||
|
||||
软件外部质量:功能性、效率、易用性、可靠性、可移植性,主要由测试工程师关注
|
||||
|
||||
软件内部质量:可维护性,主要由开发工程师关注
|
||||
|
||||

|
||||
|
||||
### 功能性
|
||||
|
||||
适合性:功能是不是用户需要的
|
||||
|
||||
准确性:功能是否准确,计算精度是否达到要求,是否和需求规格严格一致
|
||||
|
||||
互操作性:不同软件之间互操作
|
||||
|
||||
保密安全性:软件产品保护信息和数据的能力,数据从产生、传输、存储是否全程加密
|
||||
|
||||
功能依从性:要考虑国际标准、国家标准、行业标准、企业内部规范等
|
||||
|
||||
### 效率
|
||||
|
||||
时间特性
|
||||
|
||||
资源利用性
|
||||
|
||||
效率的依从性
|
||||
|
||||
### 易用性
|
||||
|
||||
易理解性
|
||||
|
||||
易学性
|
||||
|
||||
易操作性
|
||||
|
||||
吸引性
|
||||
|
||||
易用性的依从性
|
||||
|
||||
### 可靠性
|
||||
|
||||
成熟性:软件对于内部的问题能够很好的处理
|
||||
|
||||
容错性:软件对外部错误能够很好的处理
|
||||
|
||||
易恢复性:易恢复性是为了保证出现故障以后能恢复
|
||||
|
||||
可靠性的依从性
|
||||
|
||||
### 可移植性
|
||||
|
||||
适应性
|
||||
|
||||
易安装性
|
||||
|
||||
共存性
|
||||
|
||||
易替换性
|
||||
|
||||
可移植性的依从性
|
||||
|
||||
### 可维护性
|
||||
|
||||
易分析性
|
||||
|
||||
易改变性
|
||||
|
||||
稳定性
|
||||
|
||||
易测试性
|
||||
|
||||
可维护性的依从性
|
||||
|
|
@ -0,0 +1,157 @@
|
|||
---
|
||||
title: 软件需求
|
||||
date: 2023-04-12 20:07:02.2
|
||||
updated: 2023-04-12 20:07:02.2
|
||||
url: /archives/ruanjainxuqiu
|
||||
categories:
|
||||
- 软件测试
|
||||
tags:
|
||||
- 测试基础
|
||||
---
|
||||
|
||||
## 需求工程
|
||||
|
||||
### 需求开发
|
||||
|
||||
- 需求获取
|
||||
|
||||
从用户那里获取原始需求,即用户的真实想法
|
||||
|
||||
- 需求分析
|
||||
|
||||
将用户的需求具体化或者条目化
|
||||
|
||||
- 需求定义
|
||||
|
||||
将分析出来的需求写成需求规格,完成需求规格说明书(SRS)
|
||||
|
||||
- 需求验证
|
||||
|
||||
需求人员通过一些原型工具,把确定好的需求实现成一个界面,演示给用户看,进行确认验证
|
||||
|
||||
### 需求管理
|
||||
|
||||
- 需求分配
|
||||
|
||||
分配给多个需求人员协同一起进行需求分析
|
||||
|
||||
- 需求评审
|
||||
|
||||
保证项目组所有人对需求的理解是一致的,保证 需求从设计角度和测试角度都是可以实施的
|
||||
|
||||
- 需求基线
|
||||
|
||||
评审后的需求规格作为标准文档供项目组成员使 用,保证大家拿到的需求规格是一致的、完整的
|
||||
|
||||
- 需求跟踪
|
||||
|
||||
保证设计和测试是按照需求规格来的
|
||||
|
||||
- 需求变更
|
||||
|
||||
项目过程中对需求规格进行修改的过程
|
||||
|
||||
## 需求规格说明书内容
|
||||
|
||||
- 产品环境介绍
|
||||
- 软件在什么环境下使用
|
||||
- 搭建什么配置的测试环境
|
||||
- 用户特征
|
||||
- 软件给谁用
|
||||
- 测试人员需根据这些用户特征,站用户的角度而 去考虑如何测试
|
||||
- 假设和依赖关系:开发语言、开发环境
|
||||
- 用户接口
|
||||
- 功能需求:软件的基本功能
|
||||
- 性能需求
|
||||
- 技术限制
|
||||
- 软件接口:与外部软件的接口(软件模型中的互操作性)
|
||||
- 标准符合性:软件质量模型中的功能性依从性
|
||||
- 需求分级
|
||||
- 螺旋模型可以根据需求分级来确定哪些功能先做
|
||||
- 测试用例的重要级别和需求分级相关
|
||||
|
||||
## 同行评审
|
||||
|
||||
来源于IBM
|
||||
|
||||
**目的**:用于检查研发工作成果是否有问题
|
||||
|
||||
**常见的工作成果物**
|
||||
|
||||
- 管理类
|
||||
- 项目计划
|
||||
- 软件开发计划
|
||||
- 软件测试计划
|
||||
- 技术类
|
||||
- 需求规格
|
||||
- 概要设计、详细设计、代码
|
||||
- 测试方案、测试用例、测试报告
|
||||
- 程序、用户手册、帮助文档
|
||||
|
||||
**分类**
|
||||
|
||||
- 正规检视:仅针对基础性的技术类工作成果物
|
||||
- 技术评审会议
|
||||
- 管理类工作成果物
|
||||
- 测试的工作成果物
|
||||
- 走查(邮件审核):代码、用户手册、帮助
|
||||
|
||||
## 需求评审
|
||||
|
||||
**角色和职责**
|
||||
|
||||
被评审工作成果物相关的人
|
||||
|
||||
项目经理、设计人员、测试人员、用户
|
||||
|
||||
**评审流程**
|
||||
|
||||
1. 需求提交SRS
|
||||
|
||||
2. 项目经理确定评审专家并提供SRS、评审表单、评审checklist
|
||||
|
||||
(可选)需求较复杂或不好理解可召开介绍会议
|
||||
|
||||
3. 评审专家评审并提供评审反馈
|
||||
|
||||
4. 项目经理汇总评审反馈给需求
|
||||
|
||||
5. 组织评审会议,需求逐一确认每条评审意见
|
||||
|
||||
(可选)针对评审意见可召开第三小时会议
|
||||
|
||||
6. 需求人员确认评审意见后修改需求规格
|
||||
|
||||
7. 评审专家确认修改是否正确
|
||||
|
||||
8. 最后需求规格正式发布
|
||||
|
||||
## 需求跟踪
|
||||
|
||||
开发:需求项-模块-函数-代码
|
||||
|
||||
测试:需求项-测试项-测试用例-缺陷
|
||||
|
||||
**作用:**
|
||||
|
||||
避免有些需求被遗漏
|
||||
|
||||
需求变更时能很快确定哪些地方需要同步修改
|
||||
|
||||
## 需求变更
|
||||
|
||||
**变更原因**
|
||||
|
||||
- 用户需求变化
|
||||
- 缺陷导致
|
||||
- 需求跟踪引起
|
||||
|
||||
**变更流程**
|
||||
|
||||
1. 需求发起变更请求
|
||||
2. CCB审核是否变更(基于成本和进度影响)
|
||||
3. 如果能变更,开发给出变更方案1、技术能否实现,2、时间进度影响
|
||||
4. 评审变更方案
|
||||
5. 需求人员修改需求
|
||||
6. 重新进行需求评审流程
|
||||
7. 评审通过,需求跟踪
|
||||
|
|
@ -0,0 +1,52 @@
|
|||
---
|
||||
title: 饥荒联机版专用服务器 For Docker
|
||||
date: 2023-08-19 17:52:04.122
|
||||
updated: 2023-08-19 17:59:59.353
|
||||
url: /archives/ji-huang-lian-ji-ban-zhuan-yong-fu-wu-qi-fordocker
|
||||
categories:
|
||||
- Docker
|
||||
tags:
|
||||
- Docker
|
||||
---
|
||||
|
||||
> 原作者:https://github.com/hujinbo23/dst-admin-go
|
||||
|
||||
拉取镜像
|
||||
```shell
|
||||
docker pull hujinbo23/dst-admin-go:1.1.8
|
||||
```
|
||||
|
||||
## 启动容器
|
||||
启动容器命令我修改了一下,加了一个容器name和映射路径方便查看游戏文件
|
||||
```shell
|
||||
docker run -v ${HOME}/.klei/DoNotStarveTogether:/root/.klei/DoNotStarveTogether --name Cluster -d -p 8082:8082 hujinbo23/dst-admin-go:1.1.8
|
||||
```
|
||||
|
||||
查看安装日志
|
||||
```
|
||||
docker logs -f --tail 100 Cluster
|
||||
```
|
||||
|
||||
## 访问控制台面板
|
||||
IP:8082
|
||||
|
||||
## 修改系统设置
|
||||
我修改后的本地映射路径为:/root/.klei/DoNotStarveTogether
|
||||
所以系统设置中对应的路径要进行修改,游戏启动后可以在此路径查看游戏存档文件
|
||||
```
|
||||
游戏备份路径
|
||||
/root/.klei/DoNotStarveTogether
|
||||
|
||||
mod下载路径
|
||||
/root/.klei/DoNotStarveTogether
|
||||
|
||||
服务器文件夹名
|
||||
Cluster_1
|
||||
```
|
||||
|
||||
如图所示
|
||||

|
||||
|
||||
其它设置请自定义
|
||||
|
||||
|
||||
Loading…
Reference in New Issue